Getting Started with Recommendations and Boosting
Signals provide the data that Fusion uses to generate collaborative recommendations. The simplest way to get started is to enable signals and recommendations in one of your primary collections.
Once you do this, Fusion automatically creates a set of default objects and begins creating and updating collections of recommendations on a regular schedule.
| Content-based recommendations can be used without enabling signals or recommendations, but they require manual configuration. |
Enabling signals
Signals are enabled by default for new collections when you have a Fusion license installed. You can enable or disable signals for any collection at Collections > Collections Manager.
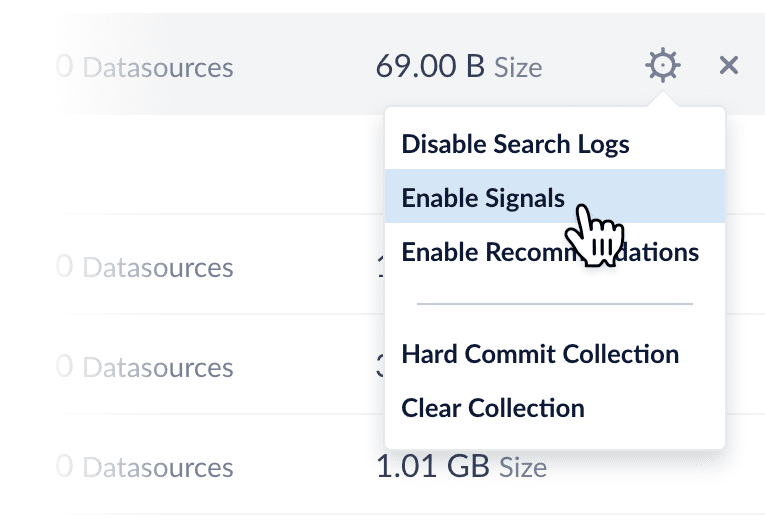
Enabling signals automatically creates a set of aggregation jobs which create the input data for recommendations. See Signals and Aggregations for complete details.
Enabling recommendations
Recommendations are not enabled by default; you can do this at Collections > Collections Manager.
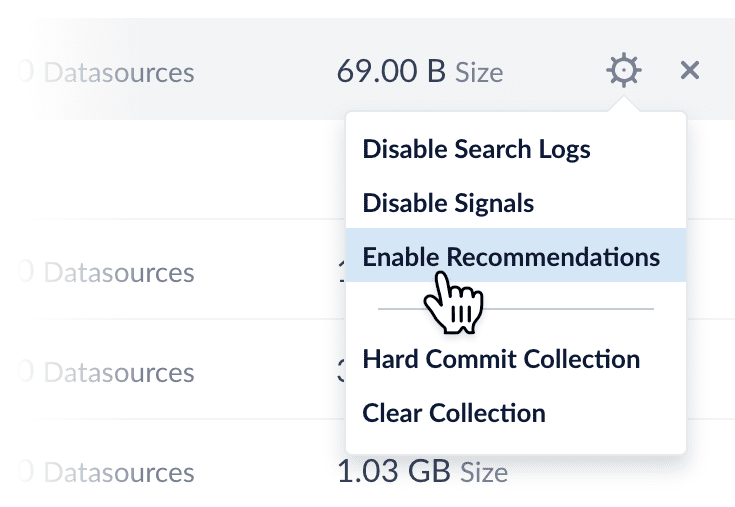
When you enable recommendations, this automatically enables the items-for-user and items-for-item recommendation methods. To use additional recommendation methods, you must configure them separately.
Default objects for recommendations
When recommendations are enabled, Fusion automatically creates a default set of collections, jobs, schedules, and query pipelines that provide basic functionality for recommendations.
You can tune the default jobs and pipelines as needed to refine the results, or create new ones, then configure your search application to request recommendations from the query pipelines.
See also the default objects created when you enable signals. These must already exist when you enable recommendations.
Collections
-
COLLECTION_NAME_items_for_item_recommendationsCollection to hold generated item-item similarities (by default 10 per item). No
user_id_sdata is present. A Recommend Items for Item query pipeline stage can use the similarities to return item recommendations. For example, a query in whichdoc_id_s = docAwould return an ordered list of otherdoc_id_svalues for documents that are similar to documentdocA, along with the similarities. For example:[("docB", 0.83), ("docC", 0.55), ("docD", 0.43), …, ("docK", 0.22)]. -
COLLECTION_NAME_items_for_user_recommendationsCollection to hold recommended items for a user. By default the job creates 10 recommendations per user.
Job and schedule
Enabling recommendations creates one new ALS Recommender job, which consumes the output of the signals aggregation jobs.
Job |
|
Default input collection |
|
Default output collections |
|
Default trigger |
None; schedule or start this job manually. |
As suggested by the output collection names, this default job produces recommender data for items-for-user and items-for-item recommendations.
The COLLECTION_NAME_user_item_preferences_aggregation job provides input data for this job and must run before it. See SQL Aggregations for details.
|
Fusion does not automatically create a Query-to-Query Similarity job, which is needed for certain recommender types.
Query pipelines
-
COLLECTION_NAME_items_for_user_recommendationsQuery pipeline to generate recommendations of items for a user.
-
COLLECTION_NAME_items_for_item_recommendationsQuery pipeline to generate recommendations of items similar to an item.
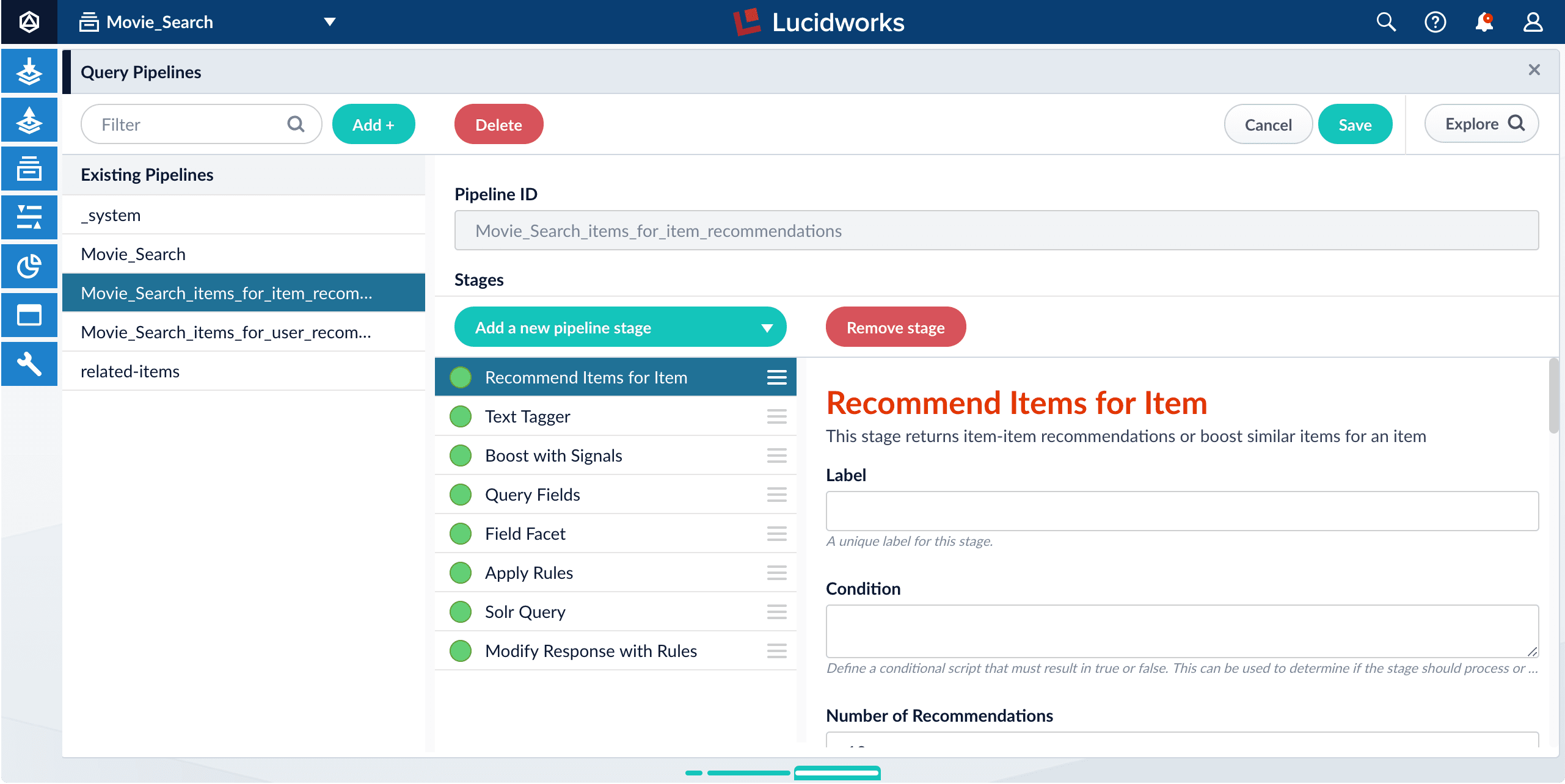
-
COLLECTION_NAME_queries_query_recsQuery pipeline to generate queries-for-query recommendations using a model created by the Query-to-Query Similarity job.