Parallel Bulk Loader (PBL)
Fusion Parallel Bulk Loader (PBL) jobs enable bulk ingestion of structured and semi-structured data from big data systems, NoSQL databases, and common file formats like Parquet and Avro.
The Parallel Bulk Loader leverages the popularity of Spark as a prominent distributed computing platform for big data. A number of companies invest heavily in building production-ready Spark SQL data source implementations for big data and NoSQL systems, much as Lucidworks has done for Solr. The Parallel Bulk Loader uses connectors provided by the experts who develop these complex systems.
Available data sources
The Parallel Bulk Loader can load documents from any system that implements the Data Sources API for Spark SQL 2.2.1 or later.
These are data sources that the Parallel Bulk Loader can use. For data sources that use Spark SQL connectors, the source of the connector is indicated.
-
Solr databases
Connector (Lucidworks): spark-solr
-
Files in these common formats: JSON, CSV, XML, Apache Avro, and Apache Parquet
-
JDBC-compliant databases
-
Apache HBase databases
Connector (Hortonworks): Apache Spark - Apache HBase Connector
-
Datasets accessible through Apache Hive
-
Apache Cassandra NoSQL databases
Connector (DataStax): Spark-Cassandra connector
-
Elastic databases
Connector: Elasticsearch-Hadoop connector
Use the package:
org.elasticsearch:elasticsearch-spark-20_2.11:6.2.2 -
MongoDB databases
-
Riak databases
-
Couchbase NoSQL databases
Connector: Couchbase-Spark connector
Use the package:
com.couchbase.client:spark-connector_2.11:2.2.0 -
Redis in-memory data structure stores
-
Google data sources, including Google Analytics, Sheets, and BigQuery
Connectors:
-
Microsoft Azure DataLake, Cosmos DB, and SQL Database
Key features
Key features of the Parallel Bulk Loader are:
-
Load distribution. To distribute load and maximize performance, the Parallel Bulk Loader parallelizes operations and distributes them across the Fusion Spark cluster.
-
No parsing. No parsing is needed. The Spark Data Sources API returns a DataFrame (RDD + schema) that has an easy-to-use tabular format.
-
Dynamic resolution of dependencies. There is nothing to download or install. Users just provide the Maven coordinates of dependencies during configuration, and Spark distributes the necessary JAR files to worker nodes.
-
Leverage integration libraries. Similar to JDBC, the Parallel Bulk Loader leverages integration libraries built by the experts of the underlying systems, for example, Databricks, DataStax, Hortonworks, Elastic, Lucidworks, Microsoft, and so forth.
-
Direct write operations. The Parallel Bulk Loader writes directly to Solr (for maximum performance) or to Fusion index pipelines (for maximum flexibility).
-
Solr atomic updates. The Parallel Bulk Loader uses atomic updates to update existing documents in Solr.
-
Incremental queries. To obtain the latest changes to data sources, macros built into the Parallel Bulk Loader use timestamps to filter queries.
-
Seamless integration with Spark-NLP. Do natural language processing, including part-of-speech tagging, stemming or lemmatization, sentiment analysis, named-entity recognition, and other NLP tasks.
-
SQL joins. Use SQL to join data from multiple Solr collections.
-
Load Fusion ML models. To classify incoming documents, load Fusion Machine Learning models stored in the Fusion blob store.
-
SQL transformations. Leverage the full power of the Spark Scala’s DataFrame APIs and SQL to filter and transform data.
-
UDF and UDAF functions. Select from hundreds of user-defined functions and user-defined aggregate functions.
Differences between the Parallel Bulk Loader and Fusion classic connectors
The primary difference between the Bulk Loader and Fusion classic connectors is that the Bulk Loader uses Spark SQL and Spark/Solr integration to perform distributed reads from data sources.
Here are some examples of how the Parallel Bulk Loader performs distributed reads:
-
HBase table. To support high-volume data ingestion into Solr, the Parallel Bulk loader can distribute queries sent to HBase tables across multiple region servers.
-
Parquet files. The Parallel Bulk loader processes a directory of Parquet files in HDFS in parallel using the built-in support for computing splits in HDFS files.
-
Spark/Solr integration. With Spark/Solr integration, the Parallel Bulk Loader uses a Spark-Solr data source to send queries to all replicas of a collection, so it can read from Solr in parallel across the Spark cluster.
This diagram depicts how the Spark-Solr data source partitions queries across all shards/replicas of a Solr collection to better utilize cluster resources and to improve read performance. Most Spark-SQL data sources do something similar for their respective databases, which is one of the main benefits of using the Parallel Bulk Loader job.
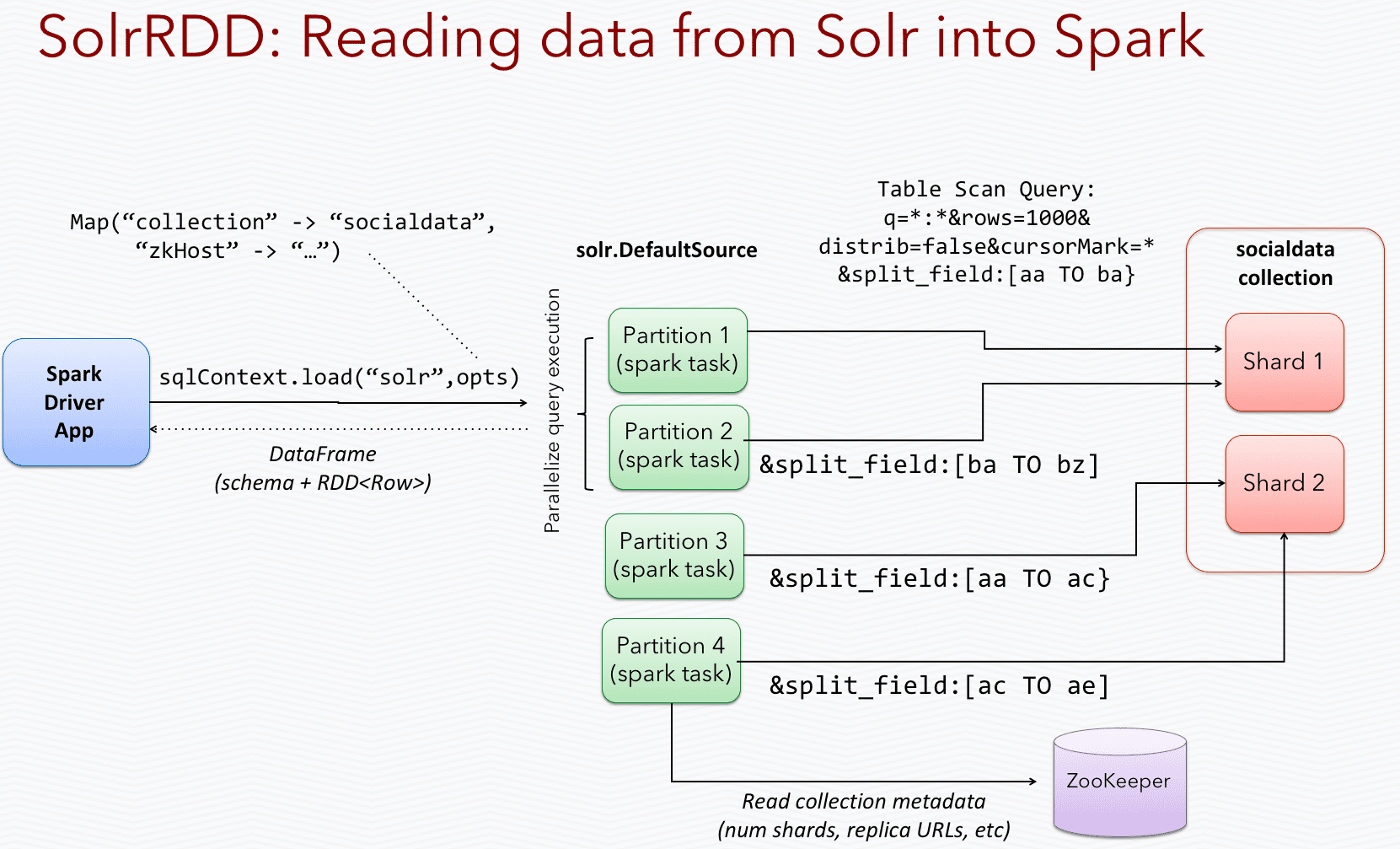
In contrast, most classic connectors have only a single-fetcher mode. To scale the fetching with classic connectors, you must distribute the connector itself, which differs from relying on the built-in parallelization of Spark.
Also, most classic connectors rely on Fusion parsers and index pipelines to prepare data for indexing, whereas no parsing is needed for the Parallel Bulk Loader, which can achieve maximum indexing performance by writing directly to Solr.