Connectors SDK
Fusion comes with a wide variety of connectors, but you can also develop custom Fusion connectors using the Connectors SDK.
To get started, clone the public repository at https://github.com/lucidworks/connectors-sdk-resources/.
-
See Java Connector Development to learn about developing a Java-based connector.
-
See Develop A Custom Connector for step-by-step instructions.
Unresolved directive in <stdin> - include::https://raw.githubusercontent.com/lucidworks/connectors-sdk-resources/{sdk-version}/README.asciidoc[lines=1..-1]
| For information about Fusion 4.2.x, see Fusion 4.2.x Connectors SDK. |
Checkpoints in the Connectors SDK
Use Cases
Incremental Re-crawl
Incremental re-crawl can be supported when a Changes API is available (e.g., Jive, Salesforce, OneDrive). When a Changes API is available, it’s necessary to provide an input parameter to be tracked, such as a date, link, page token, or other. The input parameter is generated (retrieved) while running the first job. During the next job, that parameter will be used to query the Changes API and retrieve new, modified, and deleted objects.
The SDK provides a way to store the input parameters, establishing checkpoints, and use them in the subsequent jobs.
Checkpoint Design
Fetcher implementations can emit checkpoint messages by calling:
fetchContext.emitCheckpoint(CHECKPOINT)_ID, checkpointMetadata);After the checkpoint is emitted, Fusion will handle this message as follows:
-
The checkpoint will be stored in the CrawlDB with the appropriate status.
-
The checkpoint will not be used in the current job.
In subsequent job runs, Fusion will check the CrawlDB for any previously stored checkpoints. If any are available, only those checkpoints will be sent to the fetchers; no other input types will be sent. If checkpoints are not available, all other items in the CrawlDB (Documents, FetchInputs, Errors, etc.) will be sent to the fetchers instead.
| In order to update a checkpoint, it must be emitted using its original ID. The ID is the only way the SDK controller can identify and update a checkpoint. |
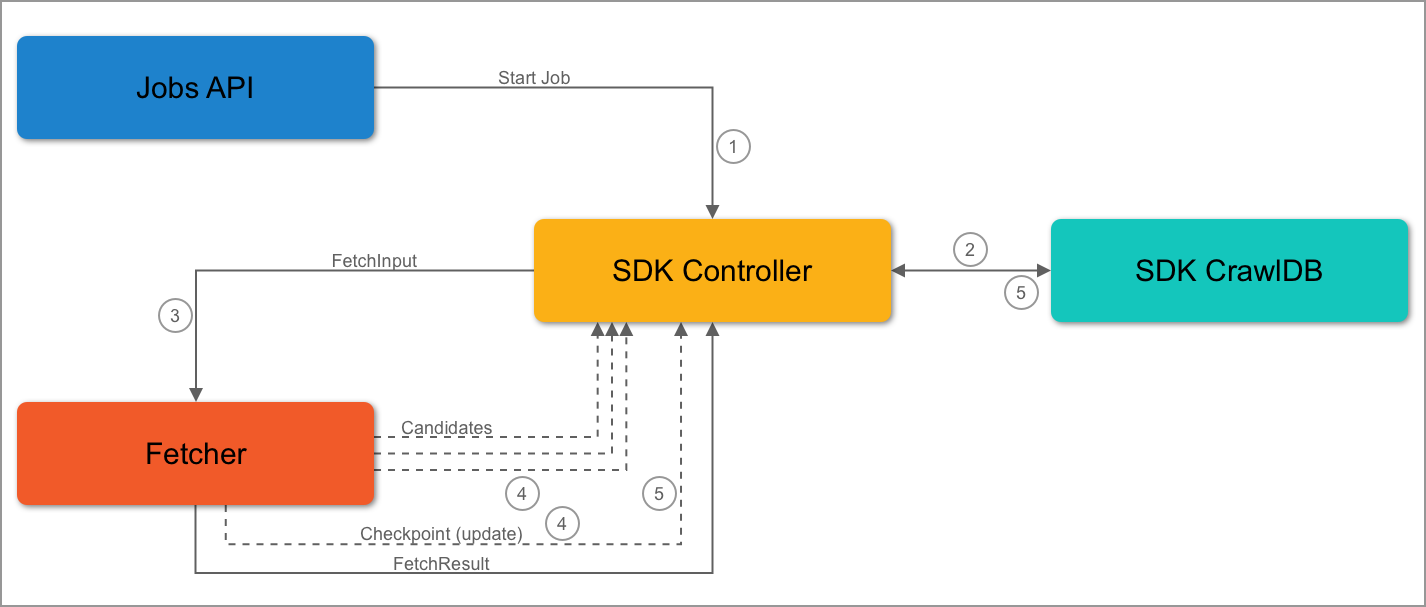
First Job Flow
-
The Jobs API sends a start job request to the SDK controller.
-
The SDK controller queries the SDK CrawlDB to check for items.
-
It’s the first job, so the SDK CrawlDB is empty. The controller will send the initial FetchInput to the fetcher.
-
During the job, the fetcher receives a FetchInput.
-
-
The fetcher can then emit candidates and/or checkpoints.
-
When the SDK controller receives a checkpoint message, the checkpoint is stored or updated in CrawlDB. It will also process the other items it has received.
-
The SDK controller will not send the checkpoint to the fetcher in the same job.
-
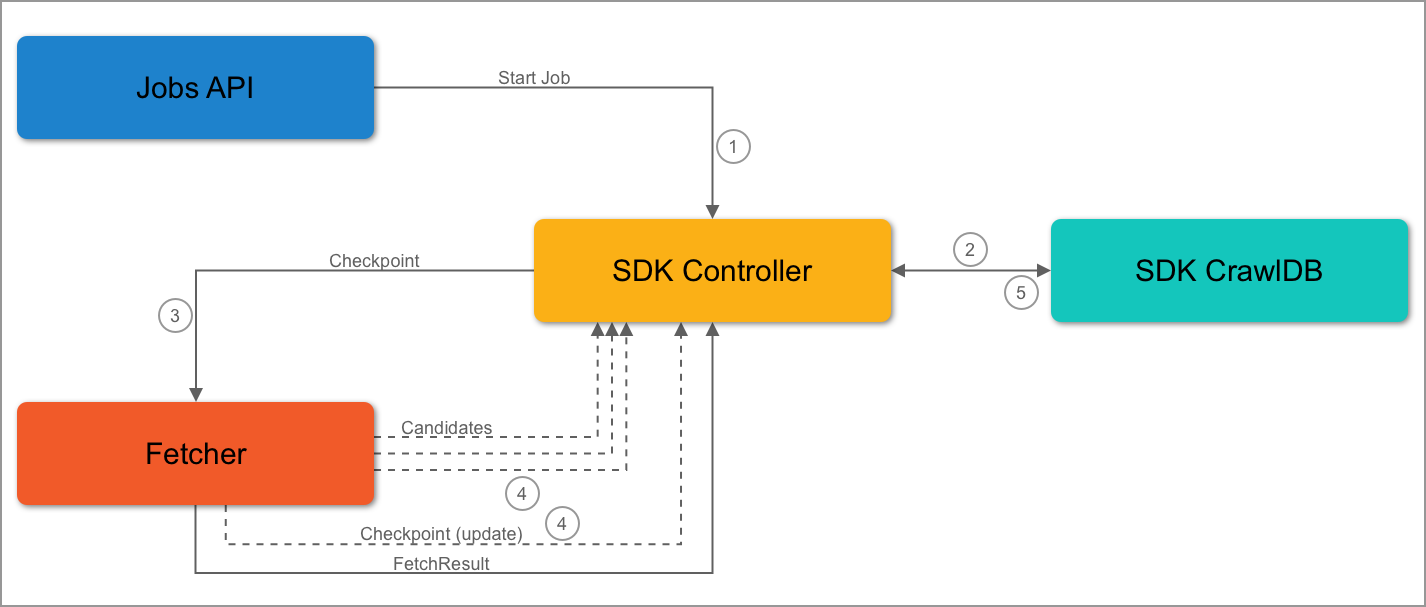
Second Job Flow
-
The Jobs API sends a start job request to the SDK controller.
-
The SDK controller queries the SDK CrawlDB to check for items.
-
It’s the second job, so checkpoints are stored in the SDK CrawlDB. The controller will send the checkpoints to the fetcher.
-
The fetcher receives and detects the checkpoints. Then, the fetcher emits candidates and updates the checkpoint. The update may take place at a later point, but the checkout must be updated.
-
If the checkpoint data matches current data, the fetcher will emit the same checkpoint.
-
-
The SDK controller will process the candidates and update the checkpoint data in the SDK CrawlDB.
Stopping a Running Job
When a job is stopped, the current state of the job is stored so that it can be completed when the job is resumed.
Stop Handling Design
The SDK controller will keep track of the incomplete/complete items during a job. An incomplete item is an item that was emitted as a candidate but has not been sent to the fetcher to be processed. Alternatively, the fetch implementation may not have emitted the FetchResult message for that item. The incomplete item is stored in the SDK CrawlDB and marked as incomplete.
A completed item is one that was emitted first as a candidate and also sent to the fetcher to be processed. The fetcher completes the process by sending back a FetchResult. This item is then marked as complete by the SDK controller by setting the blockID field in the item metadata to match the blockID of the current job.
A blockId is used to quickly identify items in the CrawlDB which may not have been fully processed, or completed. A completed job is one that naturally stops due to source data being fully processed, as opposed to jobs that are manually stopped or fail.
blockId’s identify a series of one or more jobs. The lifetime of a `blockId spans from either the start of the initial crawl (or immediately after a completed one), all the way to completion. The SDK controller will generate and use a new blockId when:
-
The current job is the first job.
-
The previous job’s state is
FINISHED.
When a job starts and the previous job did not complete, the previous job’s state is STOPPED. In this case, the previous job’s blockId is reused. The same blockId will be reused until the crawl successfully completes. The SDK controller will continue checking the CrawlDB for incomplete items, which are identified by having a blockID that doesn’t match the previous job blockID. This approach ensures all items within the job are completed before the next job beings, even if the job was stopped multiple times before completion.
When an item is considered a new candidate, the item’s blockId does not change. Later, when the item is fully processed by the fetcher, the blockId is added to the item metadata and stored in the SDK CrawlDB. The item is then considered complete but will only be sent to fetchers when a new blockId is generated.
When all items are complete, the SDK will check for checkpoints, as detailed in Checkpoint Design.
| If there are incomplete items from the previous job stored in the SDK CrawlDB, only those items will be processed during the next job. |
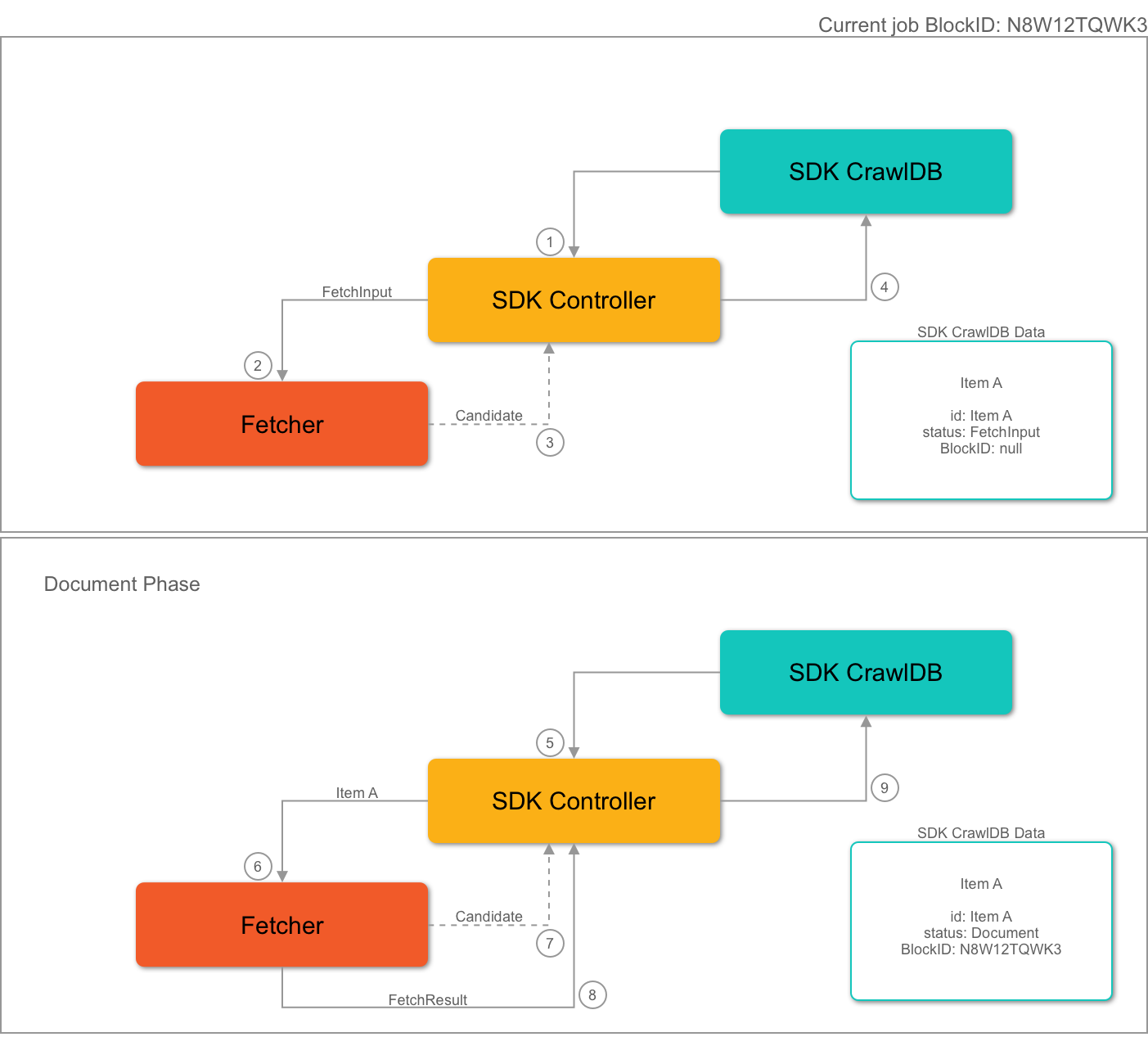
Item Completion Flow
-
The SDK controller gets a
FetchInputfrom the SDK CrawlDB and sends it to the fetcher. -
The fetcher receives the FetchInput.
-
The fetcher emits a candidate:
Item A. -
The controller receives the candidate and stores it in the SDK CrawlDB. Mandatory fields are set to the item metadata, but the
blockIdfield is not set. -
Later, in the same job, the candidate Item A is selected by the SDK controller, which sends it to a fetcher.
-
The fetcher receives the candidate and processes it.
-
The fetcher emits a
Documentfrom the candidate. -
The fetcher emits a
FetchResultto the SDK controller. -
The SDK controller receives both the Document and the FetchResult.
-
If processing the Document, the item status is updated to Document in SDK CrawlDB.
-
If processing the FetchResult, the item’s blockId is set to the current job’s blockId.
-
Transient candidates
Some connector plugins require that a new job start from the latest checkpoints and not attempt to reprocess incomplete candidates. For that purpose, emit those candidates with Transient=true. The IncrementalContentFetcher is an example.