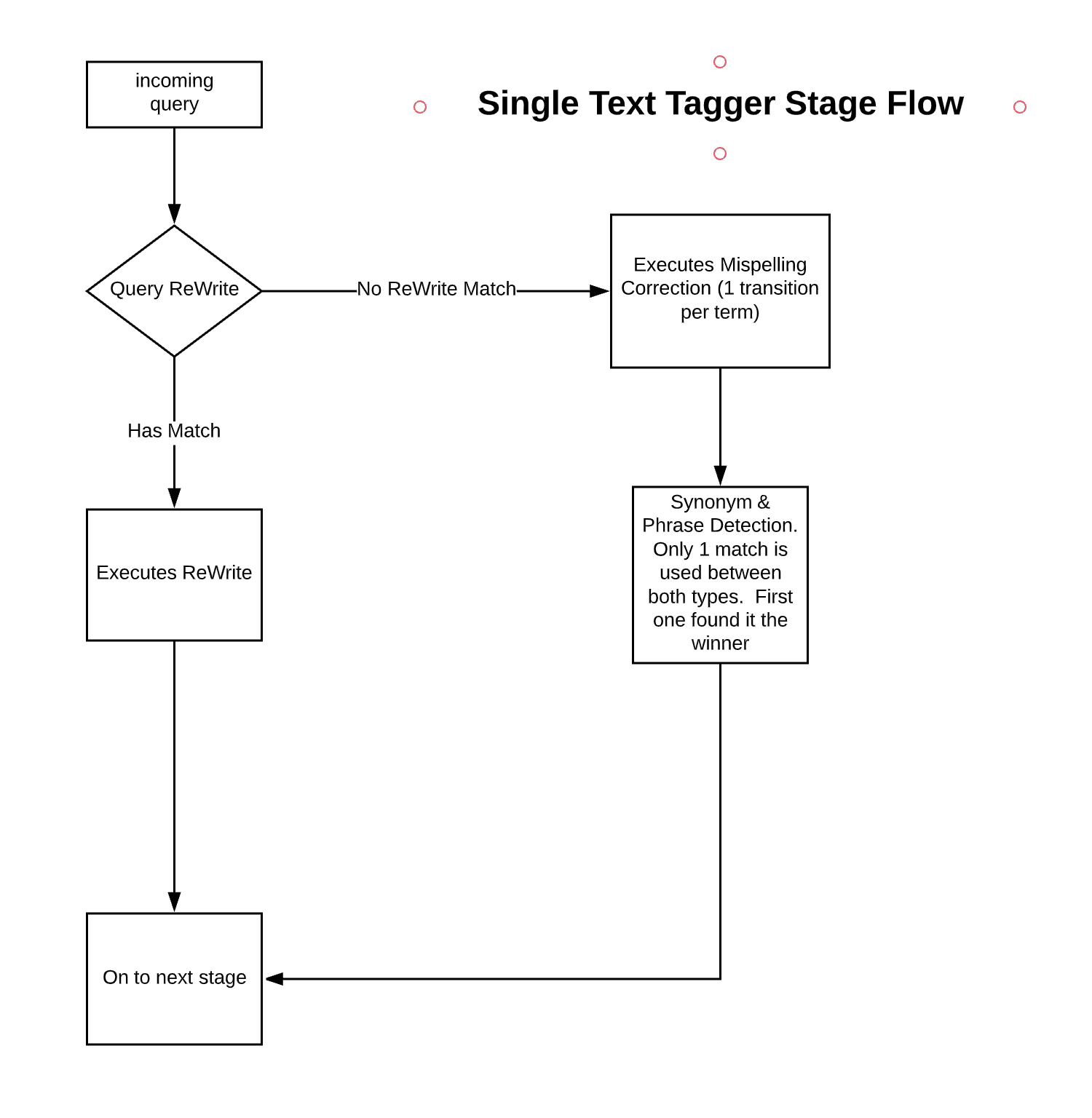
Text Tagger Stage
|
|
For Fusion 5.x.x organizations that do not have a Predictive Merchandiser license, the Solr Text Tagger handler also searches the COLLECTION_NAME_query_rewrite_staging collection in the case of the Fusion query rewriting Simulator).
|
The purpose of the search is to perform query rewriting using matches from the following items:
When the query rewrite entails boosting, the boosting is applied later in the pipeline, during the Solr Query stage.
The below diagram shows the process flow for the Text Tagger Stage:
|
|
The underlying SolrTextTagger currently only supports single-shard collections. Fusion users should ensure their COLLECTION_NAME_query_rewrite collection, or whatever collection the Text Tagger stage is configured to use, is single-sharded before enabling this stage.
|
|
|
Although this stage is available without a Fusion license, it is only effective after running Fusion jobs or creating Fusion rules. See Query Rewriting for details.
|
|
|
When entering configuration values in the UI, use unescaped characters, such as \t for the tab character. When entering configuration values in the API, use escaped characters, such as \\t for the tab character.
|
Queries a Solr text tagger request handler to perform spell correction, phrase boosting, and synonym expansion.
skip - boolean
Set to true to skip this stage.
Default: false
label - string
A unique label for this stage.
<= 255 characters
condition - string
Define a conditional script that must result in true or false. This can be used to determine if the stage should process or not.
taggerCollectionId - string
Collection to send the tagger request to; defaults to the query_rewrite collection for the application in context. Collection must contain only one shard, as the underlying Text Tagger in Solr doesn't currently support multi-shard collections.
>= 1 characters
paramToTag - string
Name of the parameter in the request containing text to tag, defaults to 'q'
Default: q
taggedOutputParam - string
Apply the matching tags to the 'paramToTag' value and set the parameter specified by this option; defaults to the value of the 'paramToTag' setting.
saveTagsInContextKey - string
Save tags in context instead of applying directly to the incoming query in this stage; allows downstream stages to apply the tags after doing other processing.
spell_corrections_enabled - boolean
If checked, then this stage will perform spell corrections on the incoming query.
Default: true
phrase_boosting_enabled - boolean
If checked, then this stage will perform phrase boosting on the incoming query.
Default: true
synonym_expansion_enabled - boolean
If checked, then this stage will perform synonym expansion on the incoming query.
Default: true
tail_rewrites_enabled - boolean
If checked, then this stage will perform tail rewrites on the incoming query.
Default: true
filterOverride - string
Use this option to override filtering for built-in tagger doc types with your own filter.
synonymExpansionBoost - number
Boost applied to the original term when doing synonym expansion; set to -1 to disable this behavior.
Default: 2
phraseBoost - number
Default boost to be applied to phrases that don't have a boost set; set to -1 to disable this behavior.
Default: 2
phraseSlop - integer
Default phrase slop to be applied to detected phrases.
Default: 10
overlaps - string
Choose the algorithm to determine which tags in an overlapping set should be retained, versus being pruned away. Options are: ALL, NO_SUB, LONGEST_DOMINANT_RIGHT; defaults to LONGEST_DOMINANT_RIGHT
Default: ALL
Allowed values: ALLNO_SUBLONGEST_DOMINANT_RIGHT
params - array[object]
object attributes:{key required : {
display name: Parameter Name
type: string
}value : {
display name: Parameter Value
type: string
}}
maxWaitMs - integer
Max time to wait for call to remote tagger collection to return; set to -1 to disable.
Default: 500
skipQueryRegex - string
Pattern to find queries to skip matching on, such as single term queries with wildcards.