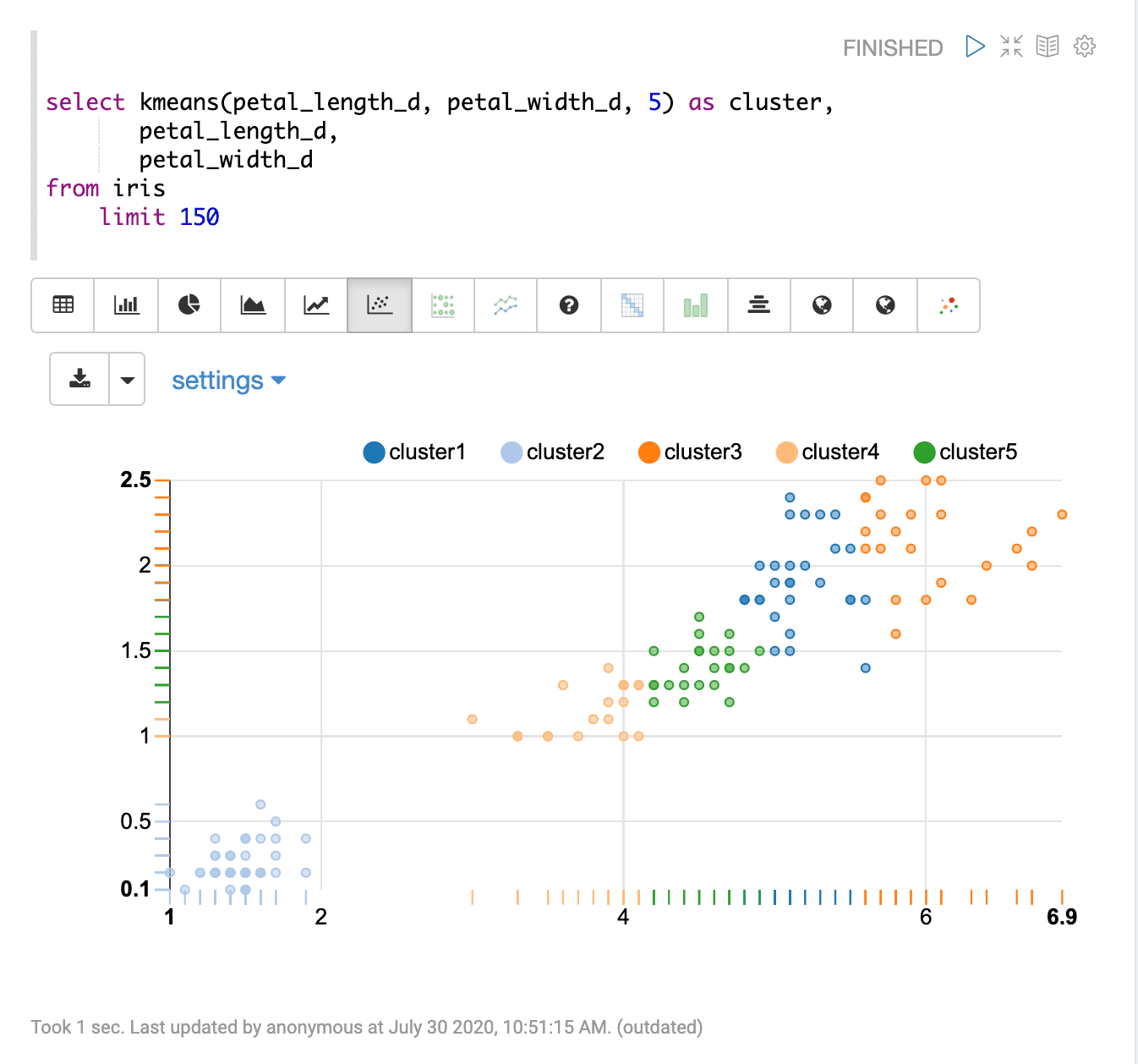
2D K-Means Clustering (kmeans)
The kmeans function performs 2D k-means clustering. 2D k-means clustering can be used to visualize patterns within 2D scatter plots. The kmeans function takes three parameters:
-
The numeric field for the first dimension
-
The numeric field for the second dimension
-
K or number of clusters
Sample syntax
select kmeans(petal_length_d, petal_width_d, 5) as cluster,
petal_length_d,
petal_width_d
from iris
limit 150Result set
The result set contains a random sample of records that match the WHERE clause. If no WHERE clause is included, the random sample will be taken from the entire result set. The size of the random sample can be controlled by the LIMIT clause. The default sample size, if no limit is applied, is 25,000.
The kmeans function returns the cluster name of each row in the result set. The two fields used for clustering are also available in the result set.
Visualization
Sample visualization of kmeans cluster with Apache Zeppelin scatter plot.