BPR Recommender Jobs
Use this job when you want to compute user recommendations or item similarities using a Bayesian Personalized Ranking (BPR) recommender algorithm.
| The ALS recommender job is deprecated. Use this recommender job instead. |
| This job is experimental. |
Default job name |
|
Input |
Aggregated signals (the |
Output |
|
query |
count_i |
type |
timstamp_tdt |
user_id |
doc_id |
session_id |
fusion_query_id |
|
|---|---|---|---|---|---|---|---|---|
Required signals fields: |
|
|
|
|
|
This job assumes that your signals collection contains the preferences of many users. It uses this collection of preferences to predict another user’s preference for an item that the user has not yet seen:
-
User. Use Training Collection User Id Field to specify the name of the user ID field, usually
user_id_s. -
Item. Use Training Collection Item Id Field to specify the name of the item ID field, usually
item_id_s. -
Interaction-value. Use Training Collection Counts/Weights Field to specify the name of the interaction value field, usually
aggr_count_i.
Compared to ALS-based recommenders, BPR-based recommenders compare a pair of recommendations for a user instead of static 0, 1 input-based recommendations as in ALS.
If using Solr as the training data source, ensure that the source collection contains the random_* dynamic field defined in its managed-schema. This field is required for sampling the data. If it is not present, add the following entry to the managed-schema alongside other dynamic fields <dynamicField name="random_*" type="random"/> and <fieldType class="solr.RandomSortField" indexed="true" name="random"/> alongside other field types.
|
Tuning tips
The BPR Recommender job has a few unique tuning parameters compared to the ALS Recommender job:
-
Training Data Filtered By Popular Items
By setting the minimum number of user interactions required for items to be included in training and recommendations, you can suppress items that do not yet have enough signals data for meaningful recommendations.
-
Filter already clicked items
This feature produces only "fresh" recommendations, by omitting items the user has already clicked. (It also increases the job’s running time.)
-
Perform approximate nearest neighbor search
This option reduces the job’s running time significantly, with a small decrease in accuracy. If your training dataset is very small, then you can disable this option.
-
Evaluate on test data
This feature samples the original dataset to evaluate how well the trained model predicts unseen user interactions. The clicks that are sampled for testing are not used for training. For example, with the default configuration, users who have at least three total clicks are selected for testing. For each of those users, one click is used for testing and the rest are used for training. The trained model is applied to the test data, and the evaluation results are written to the log.
-
Metadata fields for item-item evaluation
These fields are used during evaluation to determine whether pairs belong to the same category.
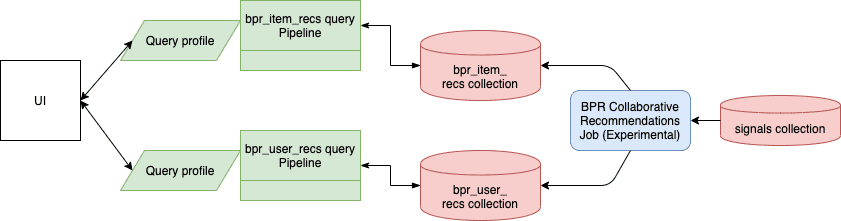
Query pipeline setup
-
For items-for-item recommendations, download the
APPName_item_item_rec_pipelines_bpr.jsonfile and import it to create the query pipeline that consumes this job’s output. See Fetch Items-for-Item Recommendations (Collaborative/BPR Method) for details. -
For items-for-user recommendations, download the
APPName_item_user_rec_pipelines_bpr.jsonfile and import it to create the query pipeline that consumes this job’s output. See Fetch Items-for-User Recommendations (Collaborative/BPR Method) for details.