Fusion SQL
Most organizations that deploy Fusion also have SQL-compliant business intelligence (BI) or dashboarding tools to facilitate self-service analytics.
The Fusion SQL service:
-
Lets organizations leverage their investments in BI tools by using JDBC and SQL to analyze data managed by Fusion. For example, Tableau is popular data analytics tool that connects to Fusion SQL using JDBC to enable self-service analytics.
-
Helps business users access important data sets in Fusion without having to know how to query Solr.
| In addition to the specified System Requirements, Fusion on Windows requires Visual C++ Redistributable for Visual Studio 2015 to start the SQL service successfully. |
Fusion SQL architecture
The following diagram depicts a common Fusion SQL service deployment scenario using the Kerberos network authentication protocol for single sign-on. Integration with Kerberos is optional. By default, the Fusion SQL service uses Fusion security for authentication and authorization.
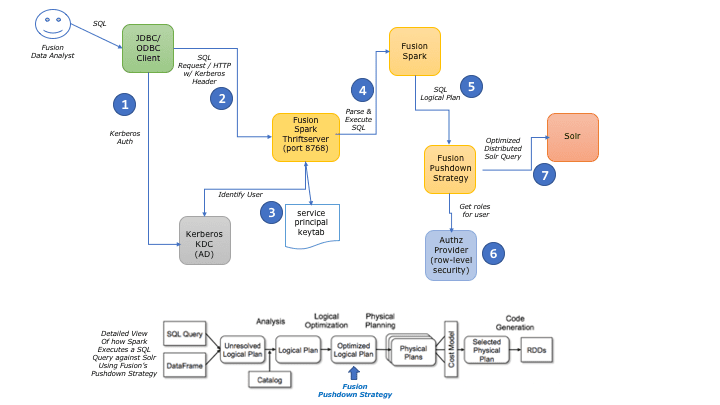
The numbered steps in the diagram are:
-
The JDBC/ODBC client application (for example, TIBCO Spotfire or Tableau) uses Kerberos to authenticate a Fusion data analyst.
-
After authentication, the JDBC/ODBC client application sends the user’s SQL query to the Fusion SQL Thrift Server over HTTP.
-
The SQL Thrift Server uses the keytab of the Kerberos service principal to validate the incoming user identity.
The Fusion SQL Thrift Server is a Spark application with a specific number of CPU cores and memory allocated from the pool of Spark resources. You can scale out the number of Spark worker nodes to increase available memory and CPU resources to the Fusion SQL service.
-
The Thrift Server sends the query to Spark to be parsed into a logical plan.
-
During the query planning stage, Spark sends the logical plan to Fusion’s pushdown strategy component.
-
During pushdown analysis, Fusion calls out to the registered AuthZ FilterProvider implementation to get a filter query to perform row-level filtering for the Kerberos-authenticated user.
By default, there is no row-level security provider but users can install their own implementation using the Fusion SQL service API.
-
Spark executes a distributed Solr query to return documents that satisfy the SQL query criteria and row-level security filter. To leverage the distributed nature of Spark and Solr, Fusion SQL sends a query to all replicas for each shard in a Solr collection. Consequently, you can scale out SQL query performance by adding more Spark and/or Solr resources to your cluster.
Fusion pushdown strategy
The pushdown strategy analyzes the query plan to determine if there is an optimal Solr query or streaming expression that can push down aggregations into Solr to improve performance and scalability. For example, the following SQL query can be translated into a Solr facet query by the Fusion pushdown strategy:
select count(1) as the_count, movie_id from ratings group by movie_idThe basic idea behind Fusion’s pushdown strategy is it is much faster to let Solr facets perform basic aggregations than it is to export raw documents from Solr and have Spark perform the aggregation. If an optimal pushdown query is not possible, then Spark pulls raw documents from Solr, and then performs any joins or aggregations needed in Spark. Put simply, the Fusion SQL service tries to translate SQL queries into optimized Solr queries. But failing that, the service simply reads all matching documents for a query into Spark, and then performs the SQL execution logic across the Spark cluster.
Which collections are registered
By default, all Fusion collections except system collections are registered in the Fusion SQL service so you can query them without any additional setup. However, empty collections cannot be queried, or even described from SQL, so empty collections will not show up in the Fusion SQL service until they have data. In addition, any fields with a dot in the name are ignored when tables are auto-registered. You can use the Catalog API to alias fields with dots in the names to include these fields.
If you add data to a previously empty collection, then you can execute either of the following SQL commands to ensure that the data gets added as a table:
show tables
show tables in `default`The Fusion SQL service checks previously empty collections every minute and automatically registers recently populated collections as a table.
You can describe any table using:
describe table-nameSee the movielens lab in the Fusion Spark Bootcamp for a complete example of working with the Fusion Catalog API and Fusion SQL service. Also read about the Catalog API.
Hive configuration
Behind the scenes, the Fusion SQL service is based on Hive. Use the /app/hive-site.xml file to configure Hive settings.
If you change hive-site.xml, you must restart the Fusion SQL service with ./sql restart (on Unix) or sql.cmd restart (on Windows).