Spark Job Drivers
A Spark "driver" is an application that creates a SparkContext for executing one or more jobs in the Spark cluster. The following diagram depicts the driver’s role in a Spark cluster:
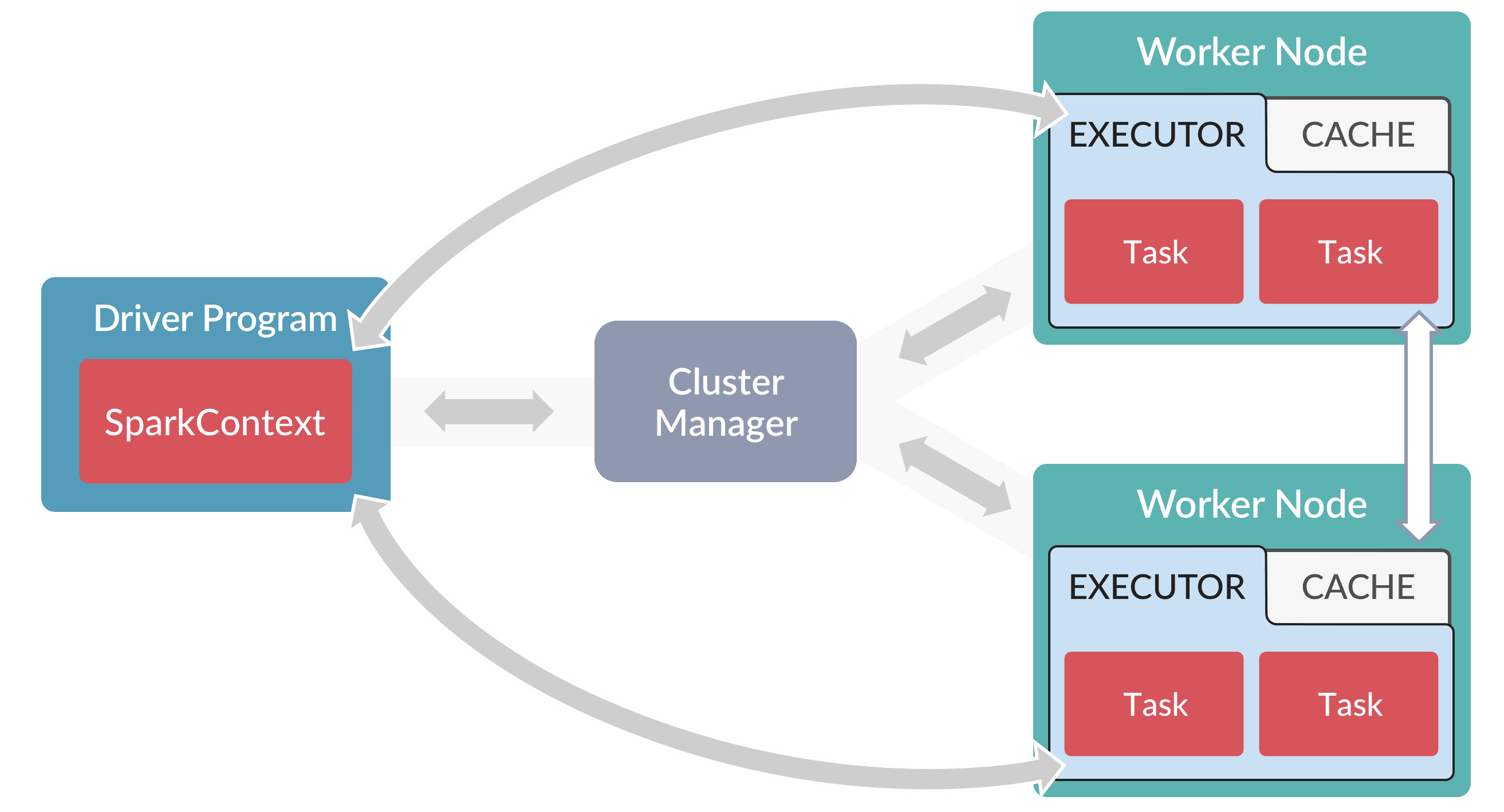
In the diagram above, the spark-master service in Fusion is the Cluster Manager.
If your Spark job performs any collect operations, then the result of the collect (or collectAsMap) is sent back to the driver from all the executors. Consequently, if the result of the collect is too big too fit into memory, you will encounter OOM issues (or other memory related problems) when running your job.
All Fusion jobs run on Spark using a driver process started by the API service.
Custom jobs
Fusion supports custom Spark jobs that are written in Scala, Java, or Python jobs and that are built using the Spark Job Workbench, a toolkit provided by Lucidworks. See the examples in the repository for details.
Drivers
Fusion has four types of job drivers:
-
Default driver. Executes built-in Fusion jobs, such as a signal aggregation job or a metrics rollup job.
-
Script-job driver. Executes custom script jobs; a separate driver is needed to isolate the classpath for custom Scala scripts.
-
Spark-shell driver. Wrapper script provided with Fusion to launch the Spark Scala REPL shell with the correct master URL (pulled from Fusion’s API) and a shaded Fusion JAR added. Launched using
{fusion-parent-unix}/fusion/5.4{sub-version}/bin/spark-shell(on Unix) or{fusion-parent-windows}\var\fusion\5.4{sub-version}\bin\spark-shell.cmd(on Windows). -
Custom-job driver. Executes custom jobs built using the Spark Job Workbench, a toolkit provided by Lucidworks to help build custom Spark jobs using Scala, Java, or Python.