Fusion 5.1.0
Release date: March 12, 2020
Component versions:
| Component | Version |
|---|---|
Solr |
8.4.1 |
ZooKeeper |
3.5.6 |
Spark |
2.4.3 |
Kubernetes |
GKE, AKS, EKS 1.17 Rancher (RKE) and OpenShift 4 compatible with Kubernetes 1.17 OpenStack and customized Kubernetes installs not supported. See Kubernetes support for end of support dates. |
Ingress Controllers |
Nginx, Ambassador (Envoy), GKE Ingress Controller Istio not supported. |
More information about support dates can be found at Lucidworks Fusion Product Lifecycle.
|
Looking to upgrade?
Check out the Fusion 5 Upgrades topic for details. |
New features
Fusion
Index Stage SDK
Lucidworks now provides an Index Stage SDK in a public repository on GitHub with all the resources you need to develop custom index stages with Java.
Clone the repository to get started:
git clone https://github.com/lucidworks/index-stage-sdkSee Gradle quickstart documentation for more information on Java Projects.
New V2 connectors
Three new V2 connectors are released:
-
Couchbase V2 - The Couchbase V2 connector uses the Couchbase Java client to retrieve data stored in Couchbase.
-
Sharepoint V2 - The SharePoint connector retrieves content and metadata from an on-premises SharePoint repository. The new connector includes many benefits associated with V2 connectors.
-
Active Directory Connector for ACLs V2 - The Active Directory Connector for ACLs (V2) indexes Access Control List (ACL) information into a configured "sidecar" Solr collection, so that it can be used by other connectors.
Apache Pulsar
Fusion 5.1.0 adds Apache Pulsar, a message bus that combines queuing with publishing-subscribing features for server-to-server messaging. A producer publishes a message to a topic and a consumer subscribes to that topic using a subscription type to receive the topic messages.
Highlights include:
-
Supports native streaming transformations through Pulsar Functions
-
Uses Apache Zookeeper for configuration management
-
Uses Apache BookKeeper for durable storage
-
Each document processed has a result object persisted to another topic
Read more about Apache Pulsar in Fusion.
More new features
-
A new metrics report Java library improves the functionality of the DevOps center.
-
Fusion creates a log file for login attempts by producing an audit file with the API gateway.
Fusion
Sentiment analysis
One major part of understanding intent is understanding sentiment. When you assign sentiment values to incoming queries, or to documents during indexing, you can leverage that data to deliver more insight to your business applications.
This release includes two state-of-the-art, pre-trained sentiment analysis models that you can use to embed sentiment scoring into your query and indexing pipelines:
| sentiment-general | sentiment-reviews |
|---|---|
A general-purpose model, trained on short sentences. Suitable for short texts and for intent prediction. See Deploy The sentiment-general Model for instructions. |
A model trained on a variety of customer reviews. Optimized for longer texts. It also supports highlighting the tokens that provide stronger sentiment. See Deploy The sentiment-reviews Model for instructions. |
See Sentiment Analysis and Prediction for more details and instructions.
Predictive Merchandiser
-
Clicking the tiles in the Analytics screen now updates the graph below to display detailed metrics.
-
The ability to switch apps from within the Rules Editor is added:
-
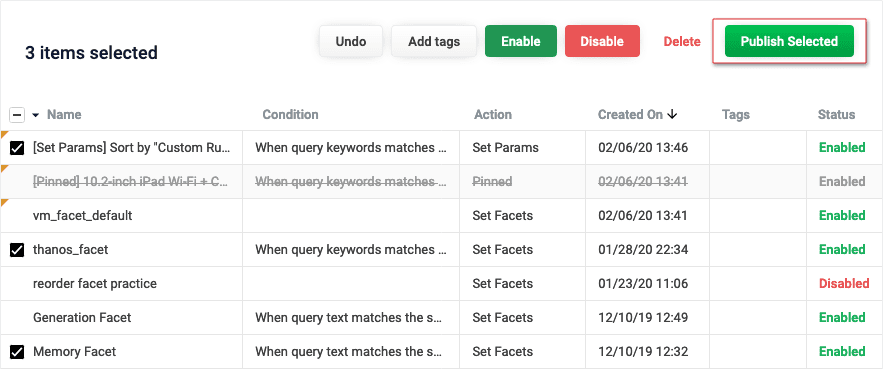
Support is added for individually selecting rules to publish in the Fusion UI:
Improvements
Fusion
-
Index stage plugins can now be uploaded directly to the Blob manager. To upload to the API with a PUT request, use the
api/index-stages/pluginsendpoint. To delete the plugin, use a DELETE request with theapi/index-stages/plugins/<pluginId>endpoint.
-
The default realms created when Fusion first starts can be overridden using the
security.initial-realm-configsspring boot properties. For example:security: initial-realm-configs: { "realmType": "jwt", "name": "jwt_okta", "enabled": true, "roleNames": [ "admin" ], "config": { "autoCreateUsers": true, "jwtIssuer": "https://dev-362383.okta.com/oauth2/default", "jwkSetUri": "https://dev-362383.okta.com/oauth2/default/v1/keys", "groups": { "groupKey": "fusion-groups", "roleMapping": [ [ "admin", "admin" ] ] } }}
-
The Index Workbench now supports "save as" functionality, like the Query Workbench.
-
Users can now import Solr synonym definitions into Fusion through the Blob Manager.
-
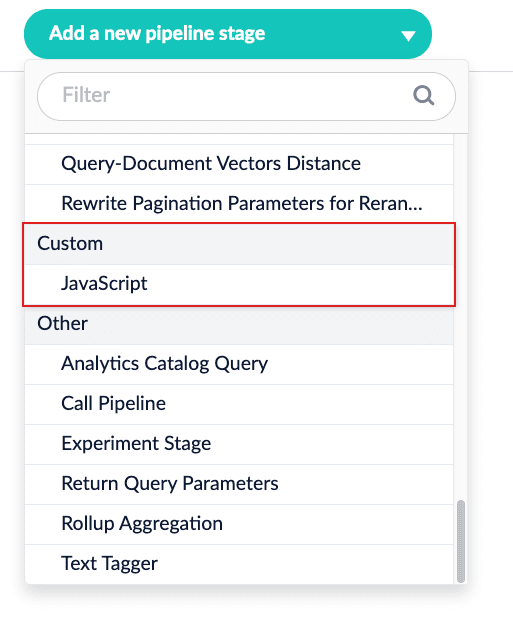
A new category, Custom, is added to index and query pipelines. Custom index pipelines include External collection query, JavaScript, and Simple. Custom query pipelines include Javascript.
-
The
externalTrafficPolicyfor the api-gateway service is now set toLocalby default. Existing users can configure this property by adding it to theircustom_fusion_values.ymlfile:api-gateway: externalTrafficPolicy: "Local"
-
Trusted realm supports IPv6 normalization and netmask in CIDR notation.
-
With Solr 8.x and 7.7.y, the
SOLR-OPTSenvironment variable, found in the Java properties, can modify themax.booleanClausesvariable.solr: image: solr:8.3 container_name: solr hostname: solr environment: ZK_HOST: zk:2181 SOLR_OPTS: -Dsolr.max.booleanClauses=5000
-
The error message generated by sending click signals to a collection that has signals disabled is improved.
-
Users with the role of "developer" now have expanded UI access.
-
Various UI improvements are made.
Fusion
-
Major updates to the Data Science Toolkit Integration. Model Devops made easy
-
Integration with open Seldon Core for custom machine learning model deployment in Fusion.
-
Follows open source standards for model creation.
-
Configure the Machine Learning index stage and query stage to interact with your deployed models.
-
Each model is containerized individually as a Docker image, allowing independent deployment with no inter-model framework dependencies.
-
Independent scaling of individual models.
-
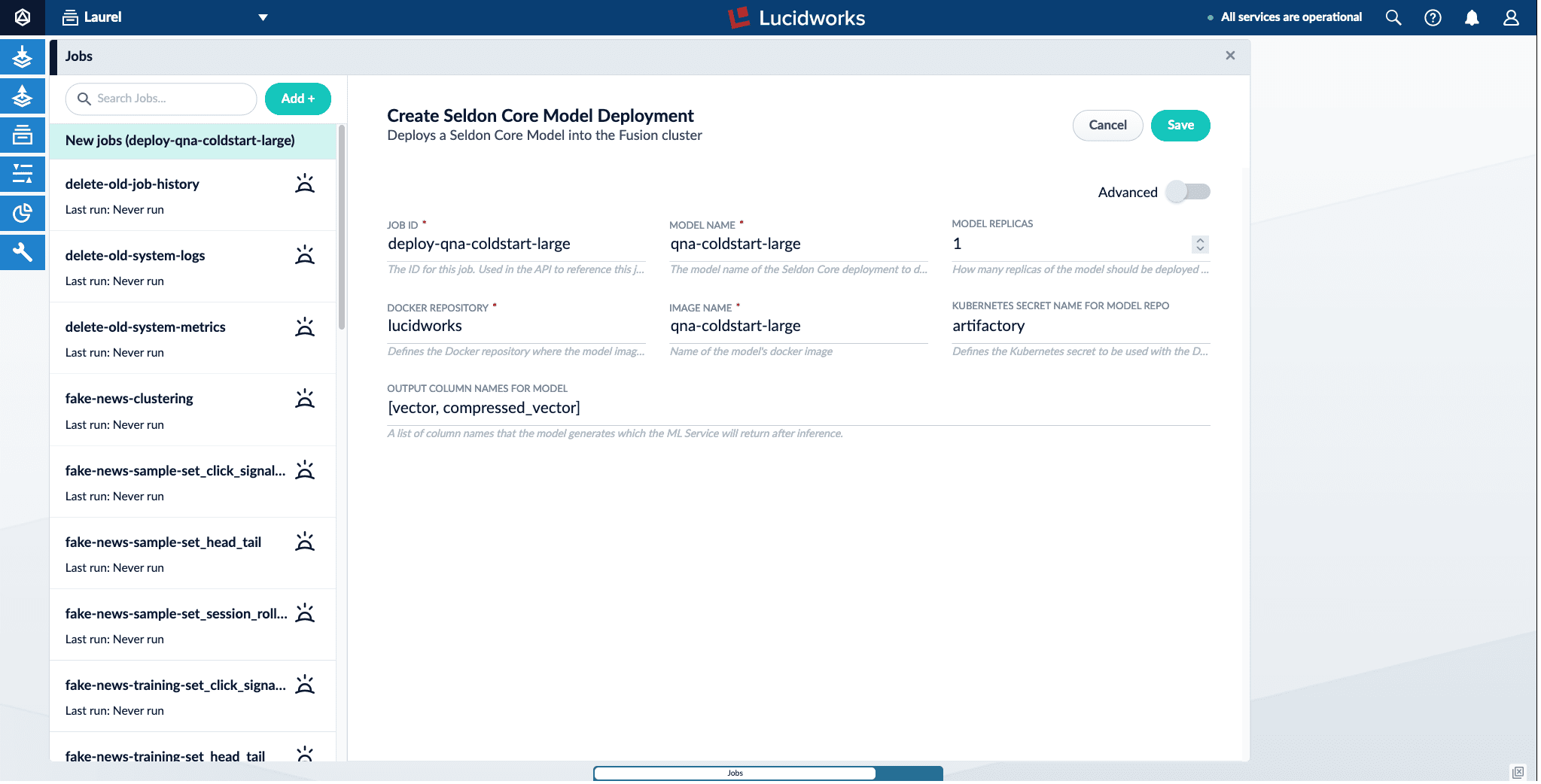
UI to deploy and delete models:
-
-
A new parameter,
loadOnStartup, is added for machine learning models. Models withloadOnStartup=truewill be automatically loaded when the machine learning service is started or the model is loaded into the machine learning service. Default behavior requires the models to be loaded on demand.
Predictive Merchandiser
Facets
-
Remove, boost, bury, or block facets by hovering over individual facets. See Use Predictive Merchandiser Facets.
-
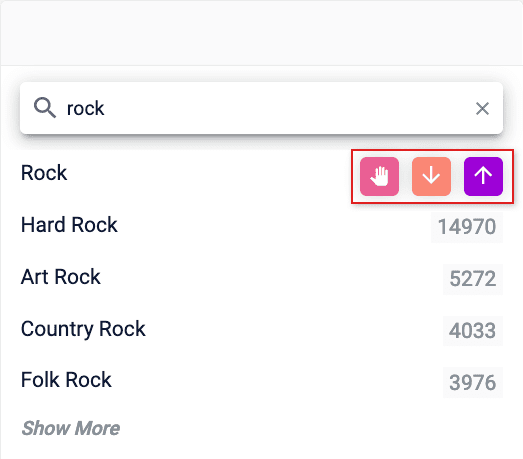
Boost, bury, or block facets from your search results:
-
Boosted facets can now be reordered with drag-and-drop:
-
Rule creation now includes selected facets as part of the rule.
-
Users can now block facet filters for facets created in the Rules Editor.
Rules
-
When creating a rule, active facets become part of the rule.
-
When creating a new rule for a term that is associated with a query rewrite rule, the new rule will apply to the rewritten term.
For example, if a query rewrite rule exists to rewrite the query
MacasMacbook Pro, creating a new rule forMacwill automatically apply the rule toMacbook Proinstead.
-
You can now assign a new rule to each of your product pins. For example, you can pin products based on a sales promotion, holiday event, etc.
-
Sort rules by priority with drag-and-drop, just as you can with facets.
-
You can now publish approved rules individually, instead of waiting for all pending approvals to be processed.
-
Rules created for a query rewrite now apply to the rewrite instead of the original term.
-
Added an optional Frequency column to the Query Rewrites dashboard for Phrases and Synonyms only, which you can use to sort and focus on high-value rewrites. You can add this column by customizing the columns for those rewrite types.
-
Added
Reasonmeta-data for head/tail rewrites, to explain the reason why the rewrite was suggested. -
Added
Typemeta-data for spell corrections rewrites, to explain whether a token-level correction or phrase-level correction is recommended. -
Added a new option for users to enable or disable query rewrite rule types.

-
Rules with high confidence ratings can be published automatically to production from the AI Jobs. Fusion 5.1 does not auto-publish from AI Jobs by default.
Other improvements
-
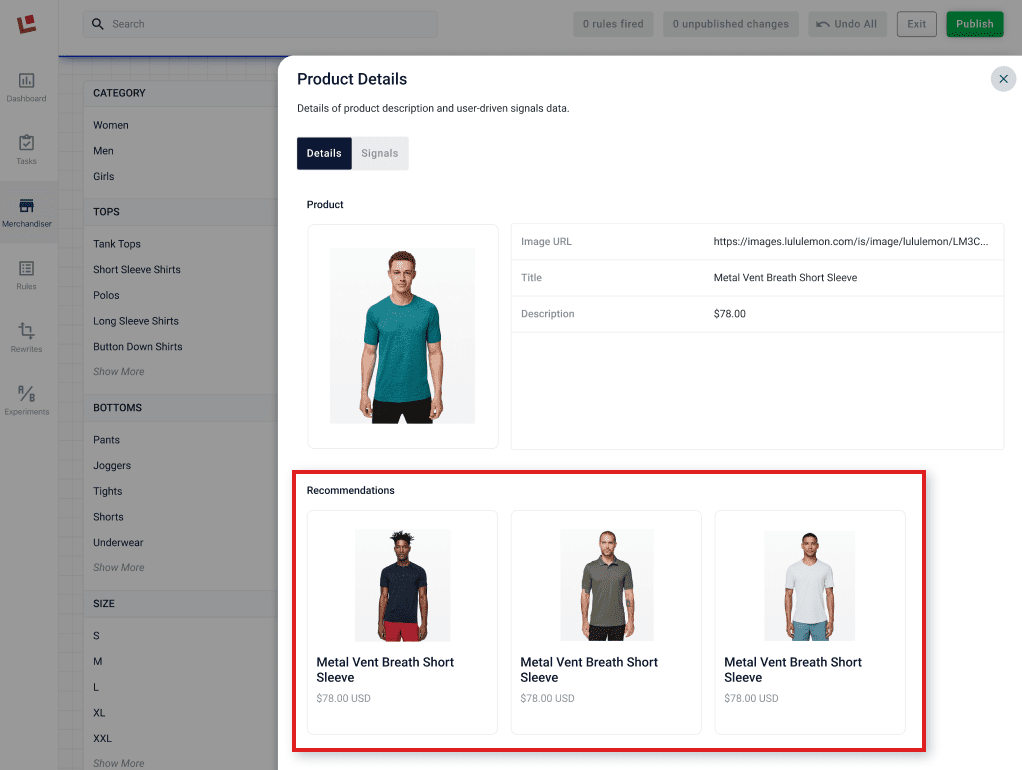
Recommended products that have been generated by signals are included in the Details panel.
-
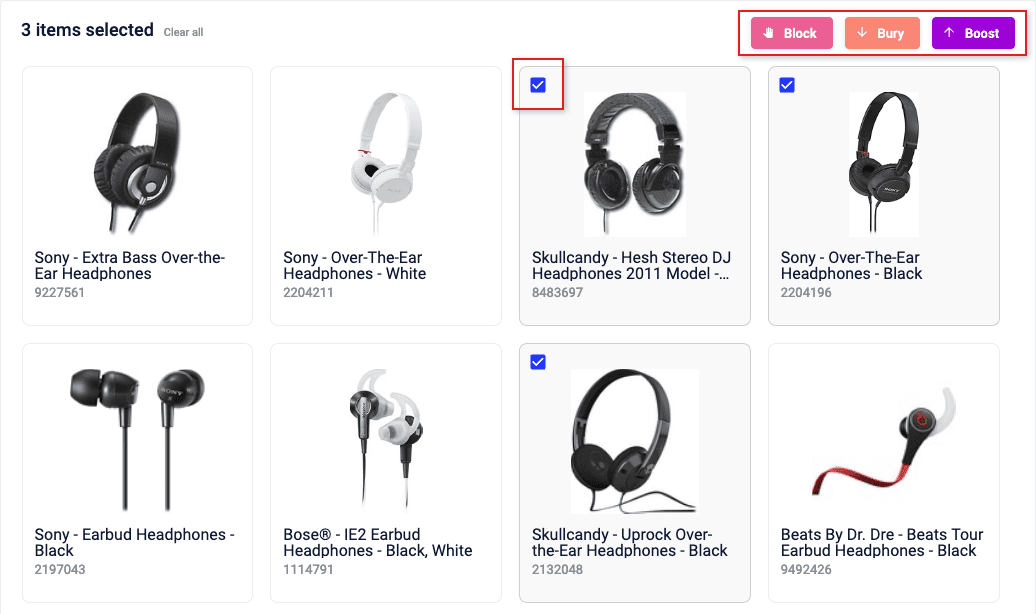
You can now boost, bury, and block multiple products at once.
-
Documents now feature an icon for drag-and-drop functionality.
-
A date range filter component is added to the Dashboard for quickly sorting analytics data:

-
Various UI improvements.
Addressed security vulnerabilities
Fusion
-
Fixed an issue with a component in the
admin-uipackage that resulted in an security alert.
Bug fixes
Fusion
-
The Parallel Bulk Loader (PBL) will no longer fail when a document fails to be uploaded to the index pipeline using
POST. Enable this functionality in the PBL configuration.
-
The Tika parser now honors MIME type parameters, for example:
{{application/vnd.wordperfect; version=5.0}}`. Previously, content MIME types parameters were not always correctly matched to types supported by Tika. This resulted in the Tika parser not recognizing content as parseable.
-
Fixed a bug that prevented files with non-ascii filenames from being uploaded to the index workbench.
-
Fixed a bug that sometimes prevented renamed files from showing up in query results after being reindexed.
-
Fixed a bug that caused the query workbench to fail to load if there were over 10,000 Solr fields.
-
Fusion no longer blocks access to the Blob Store and Collections Manager when the collections service is down.
-
The Github connector no longer authenticates with a username and password, as this functionality is deprecated. Now, a personal access token is required.
-
Connectors can now join a running job.
-
Fixed a bug that sometimes resulted in an
ArrayIndexOutOfBoundsExceptionerror when running a spell correction job.
-
Fixed a bug that prevented apps created in Fusion 4.2.x from being imported to 5.y.
-
All
zkConnectionStringsvalues can be set with a single global variable,zkConnectionString. Previously, the values were set individually per service.
-
Jupyter sessions will no longer expire while the user is still active.
-
Fixed a bug with the de-duplicate feature that allowed spurious fields to be written to Solr.
-
Fixed a bug that required a non-empty, non-root context path for deploying an application into the webapps service.
Fusion
-
Switching between apps in the Fusion UI while viewing the query rewrite tab will no longer bring you to the rules tab.
-
When multiple rules are selected in bulk, the enable and disable buttons are now inactive.
-
Fixed a bug that prevented faceting query rewrites in Internet Explorer 11.
-
Fixed a bug that disabled the option to delete query rewrite synonyms if a synonym was edited after being added.
-
Fixed a bug that prevented the user from publishing rules by type.
-
Fixed a bug that prevented query rewrite from creating multi-word synonyms.
Predictive Merchandiser
-
Fixed a bug that prevented facet list items from reappearing when unselecting a facet category.
-
Fixed a bug with the typeahead functionality of the search box.
-
Fixed a bug that prevented items in the details table from appearing.
Known issues
Fusion
-
When subscriptions are refreshed, only the original node receives the request to start or stop the subscription. This is fixed in Fusion 5.1.1.