Spark Getting Started for Fusion 4.x
The public GitHub repository Fusion Spark Bootcamp contains examples and labs for learning how to use Fusion’s Spark features.
In this section, you will walk through some basic concepts of using Spark in Fusion. For more exposure, you should work through the labs in the Fusion Spark Bootcamp.
Starting the Spark Master and Spark Worker services
The Fusion run script /opt/fusion/latest.x/bin/fusion (on Unix) or C:\lucidworks\fusion\latest.x\bin\fusion.cmd (on Windows) does not start the spark-master and spark-worker processes. This reduces the number of Java processes needed to run Fusion and therefore reduces memory and CPU consumption.
Jobs that depend on Spark, for example, aggregations, will still execute in what Spark calls local mode. When in local mode, Spark executes tasks in-process in the driver application JVM. Local mode is intended for jobs that consume/produce small datasets.
One caveat about using local mode is that a persistent Spark UI is not available. But you can access the driver/job application UI at port :4040 while the local SparkContext is running.
To scale Spark in Fusion to support larger data sets and to speed up processing, you should start the spark-master and spark-worker services.
On Unix:
./spark-master start
./spark-worker startOn Windows:
spark-master.cmd start
spark-worker.cmd startGive these commands from the bin directory below the Fusion home directory, for example, /opt/fusion/latest.x (on Unix) or C:\lucidworks\fusion\latest.x (on Windows).
|
To have the In Fusion 4.1+ In Fusion 4.0.x |
Viewing the Spark Master
After starting the master and worker services, direct your browser to http://localhost:8767 to view the Spark master web UI, which should resemble this:
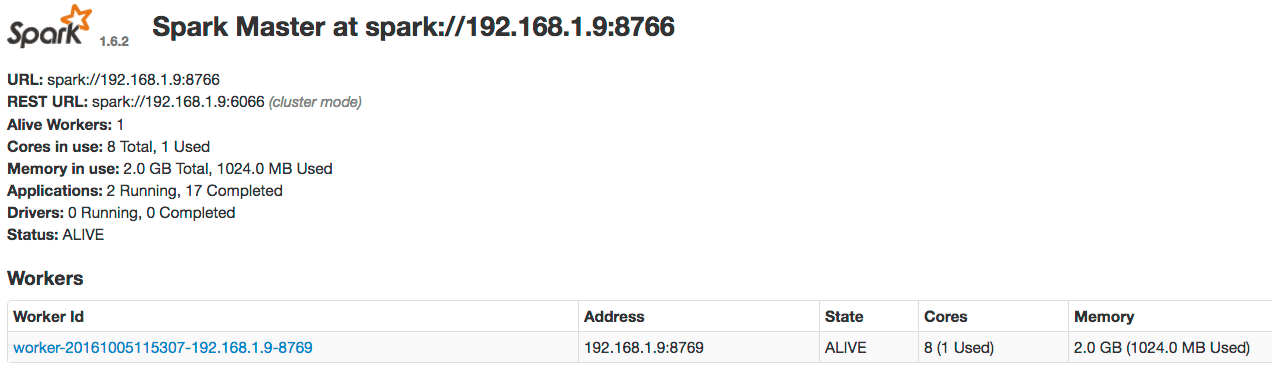
If you do not see the master UI and at least one worker in the ALIVE state, check these logs.
On Unix:
/opt/fusion/latest.x/var/log/spark-master/spark-master.log
/opt/fusion/latest.x/var/log/spark-worker/spark-worker.logOn Windows:
C:\lucidworks\fusion\latest.x\var\log\spark-master\spark-master.log
C:\lucidworks\fusion\latest.x\var\log\spark-worker\spark-worker.logUse this Fusion API request to get the status of the Spark master:
curl http://localhost:8764/api/spark/master/status
This request should return a response of the form:
[ {
"url" : "spark://192.168.1.9:8766",
"status" : "ALIVE",
"workers" : [ {
"id" : "worker-20161005175058-192.168.1.9-8769",
"host" : "192.168.1.9",
"port" : 8769,
"webuiaddress" : "http://192.168.1.9:8770",
"cores" : 8,
"coresused" : 0,
"coresfree" : 8,
"memoryused" : 0,
"memoryfree" : 2048,
"state" : "ALIVE",
"lastheartbeat" : 1475711489460
} ], ...
If you have multiple Spark masters running in a Fusion cluster, each will be shown in the status but only one will be ALIVE; the other masters will be in STANDBY mode.
| If you are operating a multi-node Spark cluster, we recommend running multiple Spark master processes to achieve high-availability. If the active one fails, the standby will take over. |
Running a job in the Spark shell
After you have started the Spark master and Spark worker, run the Fusion Spark shell.
On Unix:
./spark-shell
On Windows:
spark-shell.cmd
Give these commands from the bin directory below the Fusion home directory, for example, /opt/fusion/latest.x (on Unix) or C:\lucidworks\fusion\latest.x (on Windows).
The shell can take a few minutes to load the first time because the script needs to download the shaded Fusion JAR file from the API service.
If ports are locked down between Fusion nodes, specify the Spark driver and BlockManager ports, for example:
On Unix:
./spark-shell --conf spark.driver.port=8772 --conf spark.blockManager.port=8788
On Windows:
spark-shell.cmd --conf spark.driver.port=8772 --conf spark.blockManager.port=8788
When the Spark shell is initialized, you will see the prompt:
scala>
Type :paste to activate paste mode in the shell and paste in the following Scala code:
val readFromSolrOpts = Map(
"collection" -> "system_logs",
"fields" -> "host_s,level_s,type_s,message_txt,thread_s,timestamp_tdt",
"query" -> "level_s:[* TO *]"
)
val logsDF = spark.read.format("solr").options(readFromSolrOpts).load
logsDF.registerTempTable("fusion_logs")
var sqlDF = spark.sql("""
| SELECT COUNT(*) as num_values, level_s as level
| FROM fusion_logs
| GROUP BY level_s
| ORDER BY num_values desc
| LIMIT 10""".stripMargin)
sqlDF.show(10,false)
Press CTRL+D to execute the script. Your results should resemble these results:
scala> :paste
// Entering paste mode (ctrl-D to finish)
val readFromSolrOpts = Map(
"collection" -> "system_logs",
"fields" -> "host_s,level_s,type_s,message_txt,thread_s,timestamp_tdt",
"query" -> "level_s:[* TO *]"
)
val logsDF = spark.read.format("solr").options(readFromSolrOpts).load
logsDF.registerTempTable("fusion_logs")
var sqlDF = spark.sql("""
| SELECT COUNT(*) as num_values, level_s as level
| FROM fusion_logs
| GROUP BY level_s
| ORDER BY num_values desc
| LIMIT 10""".stripMargin)
sqlDF.show(10,false)
// Exiting paste mode, now interpreting.
warning: there was one deprecation warning; re-run with -deprecation for details
+----------+-----+
|num_values|level|
+----------+-----+
|3960 |INFO |
|257 |WARN |
+----------+-----+
readFromSolrOpts: scala.collection.immutable.Map[String,String] = Map(collection -> system_logs, fields -> host_s,level_s,type_s,message_txt,thread_s,timestamp_tdt, query -> level_s:[* TO *])
logsDF: org.apache.spark.sql.DataFrame = [host_s: string, level_s: string ... 4 more fields]
sqlDF: org.apache.spark.sql.DataFrame = [num_values: bigint, level: string]
Do not worry about WARN log messages when running this script. They are benign messages from Spark SQL
Congratulations, you just ran your first Fusion Spark job that reads data from Solr and performs a simple aggregation!
The Spark master web UI
The Spark master web UI lets you dig into the details of the Spark job. In your browser (http://localhost:8767), there should be a job named "Spark shell" under running applications (the application ID will be different than the following screenshot):

Click the application ID, and then click the Application Detail UI link. You will see this information about the completed job:

Notice the tabs at the top of the UI that let you dig into details about the running application. Take a moment to explore the UI. It can answer these questions about your application:
-
How many tasks were needed to execute this job?
-
Which JARs were added to the classpath for this job? (Look under the Environment tab.)
-
How many executor processes were used to run this job? Why? (Look at the Spark configuration properties under the Environment tab.)
-
How many rows were read from Solr for this job? (Look under the SQL tab.)
For the above run, the answers are:
-
205 tasks were needed to execute this job.
-
The Environment tab shows that one of the JAR files is named
spark-shaded-*.jarand was "Added By User". -
It took 2 executor processes to run this job. Each executor has 2 CPUs allocated to it and the
bin/spark-shellscript asked for 4 total CPUs for the shell application. -
This particular job read about 21K rows from Solr, but this number will differ based on how long Fusion has been running.
The key take-away is that you can see how Spark interacts with Solr using the UI.
Spark job tuning
Returning to the first question, why were 202 tasks needed to execute this job?
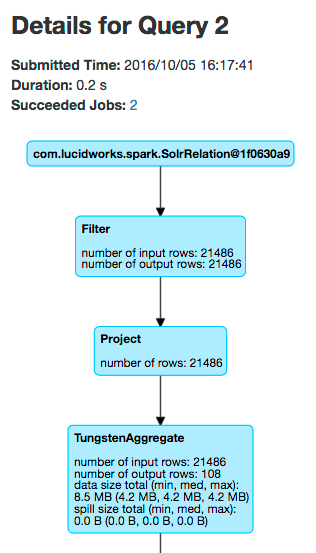
The reason is that SparkSQL defaults to using 200 partitions when performing distributed group by operations; see the property spark.sql.shuffle.partitions.
Because our data set is so small, let us adjust Spark so that it only uses 4 tasks. In the Spark shell, execute the following Scala:
spark.conf.set("spark.sql.shuffle.partitions", "4")
You just need to re-execute the final query and show command:
val readFromSolrOpts = Map(
"collection" -> "logs",
"fields" -> "host_s,port_s,level_s,message_t,thread_s,timestamp_tdt"
)
val logsDF = spark.read.format("solr").options(readFromSolrOpts).load
logsDF.registerTempTable("fusion_logs")
var sqlDF = spark.sql("""
| SELECT COUNT(*) as num_values, level_s as level
| FROM fusion_logs
| GROUP BY level_s
| ORDER BY num_values desc
| LIMIT 10""".stripMargin)
sqlDF.show(10,false)
Now if you look at the Job UI, you will see a new job that executed with only 6 executors! You have just had your first experience with tuning Spark jobs.