Scale Spark Aggregations for Fusion 4.x
Consider the process of running a simple aggregation on 130M signals. For an aggregation of this size, it helps to tune your Spark configuration.
Speed up tasks and avoid timeouts
One of the most common issues encountered when running an aggregation job over a large signals data set is task timeout issues in Stage 2 (foreachPartition). This is typically due to slowness indexing aggregated jobs back into Solr or due to JavaScript functions.
The solution is to increase the number of partitions of the aggregated RDD (the input to Stage 2). By default, Fusion uses 25 partitions. Here, we increase the number of partitions to 72. Set these configuration properties:
-
spark.default.parallelism.* Default number of partitions in RDDs returned by transformations likejoin,reduceByKey, andparallelizewhen not specified by the user:curl -u USERNAME:PASSWORD -H 'Content-type:application/json' -X PUT -d '72' "https://FUSION_HOST:6764/api/configurations/spark.default.parallelism"
-
spark.sql.shuffle.partitions.* Number of partitions to use when shuffling data for joins or aggregations.curl -u USERNAME:PASSWORD -H 'Content-type:application/json' -X PUT -d '72' "https://FUSION_HOST:6764/api/configurations/spark.sql.shuffle.partitions"
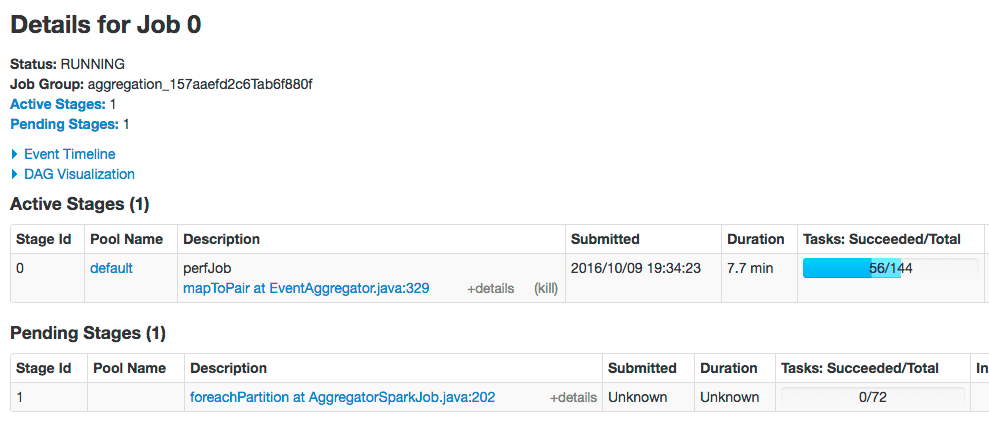
After making these changes, the foreachPartition stage of the job will use 72 partitions:
Increase rows read per page
You can increase the number of rows read per page (the default is 10000) by passing the rows parameter when starting your aggregation job; for example:
curl -u USERNAME:PASSWORD -XPOST "https://FUSION_HOST:6764/api/aggregator/jobs/perf_signals/perfJob?rows=20000&sync=false"
For example, we were able to read 130M signals from Solr in 18 minutes at ~120K rows/sec using rows=20000 vs. 21 minutes using the default 10000.
Improve job performance
You can increase performance when reading input data from Solr using the splits_per_shard read option, which defaults to 4. This configuration setting governs how many Spark tasks can read from Solr concurrently. Increasing this value can improve job performance but also adds load on Solr.