Configure AEM V2 Connector
This document explains how to configure an AEM V2 connector to crawl data in Adobe Experience Manager. Refer to the AEM reference to learn more about how this connector works. This connector is compatible with Fusion 5.5.1 and later.
Configure AEM Datasource
-
Under Indexing > Datasources, click Add, then select AEM
-
Enter a Configuration ID
-
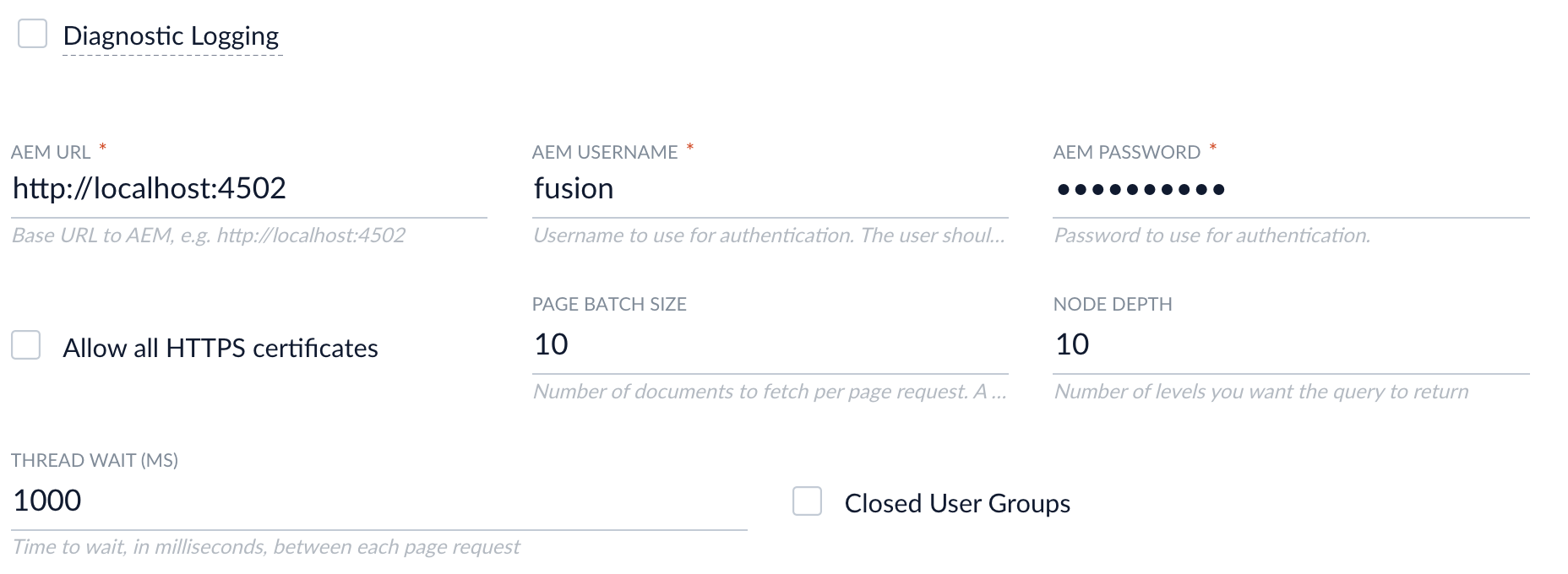
Enter the AEM URL (the URL used to access the AEM Admin UI) as well as the AEM username and password used to authenticate access to the QueryBuilder JSON Servlet.
-
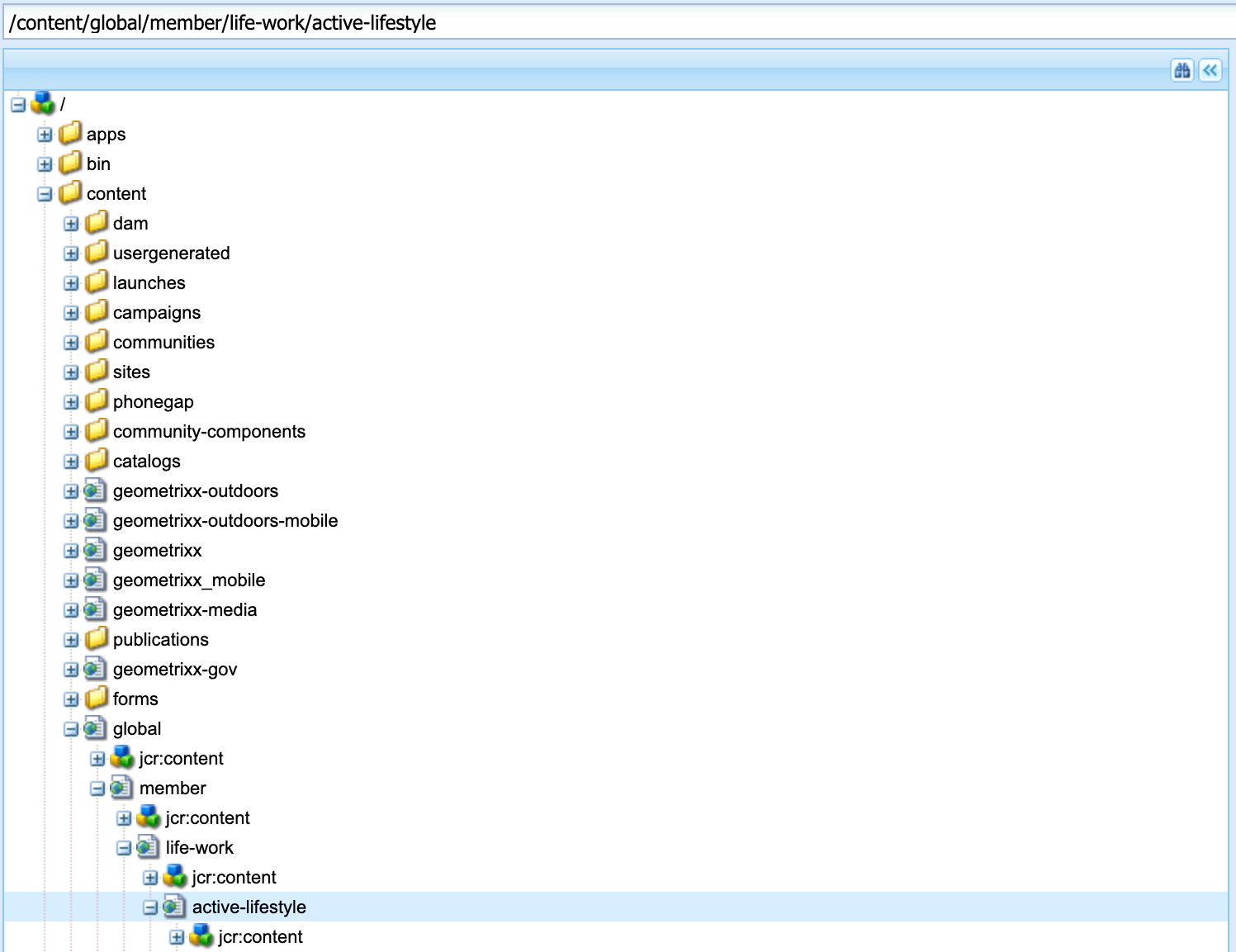
In the CRXDE UI, select a path to crawl. Enter this path into Fusion. Click Add to crawl multiple paths.

-
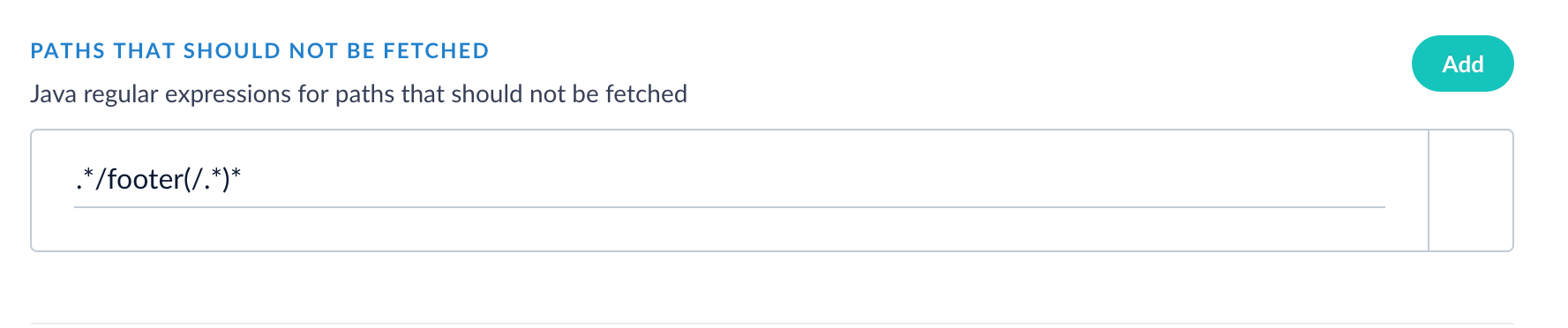
Optional: To exclude paths from the crawl, enter a Java Regular Expression (regex) that represents paths to exclude in the indexed content.
-
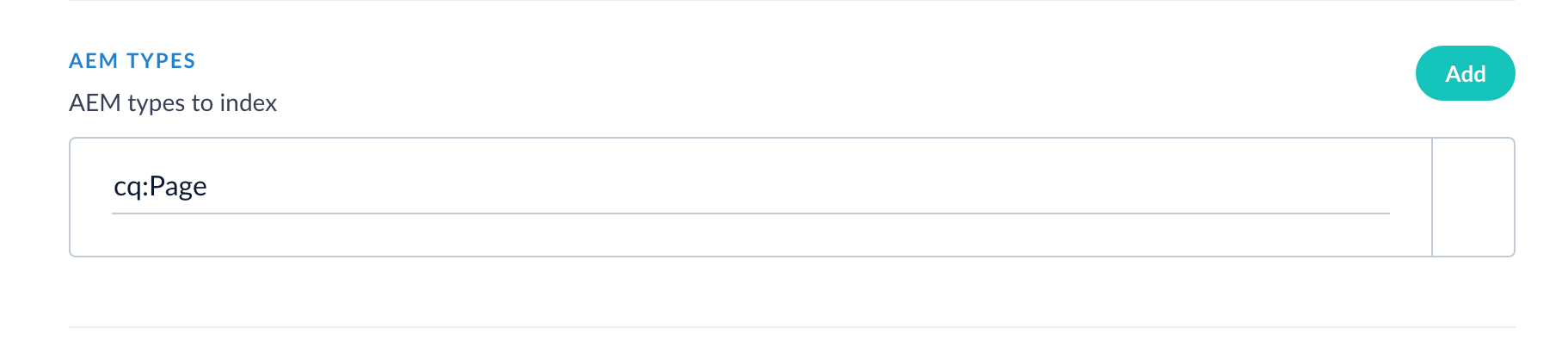
Enter the AEM type to crawl. In the CRXDE UI, this is the
jcr:primaryType. In this example, the AEM connector is configured to crawl the AEM Typecq:Page, which represents web content pages.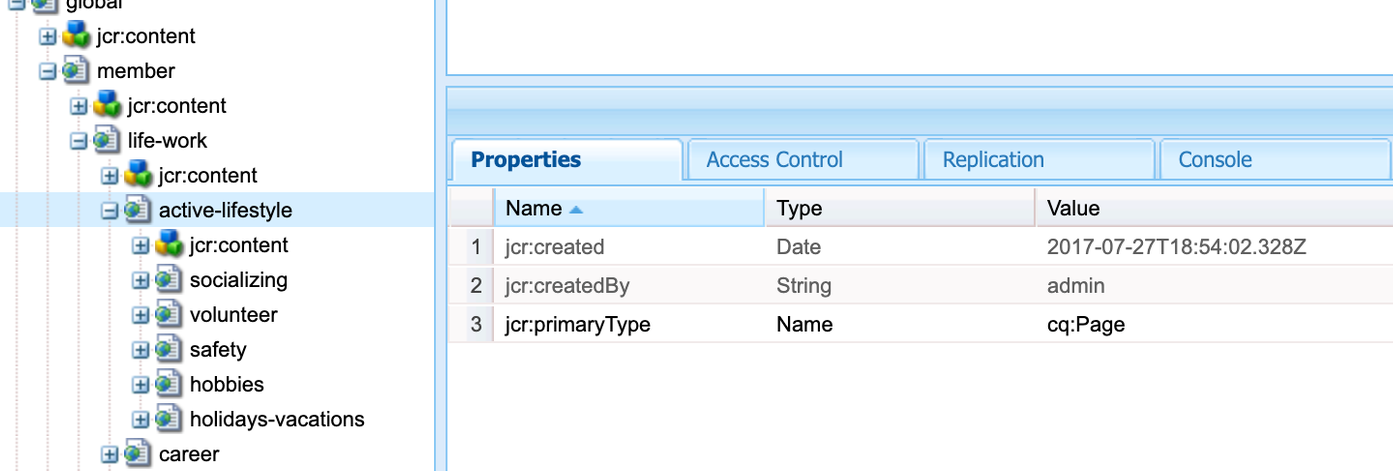
-
To index assets with a particular file extension, locate a file type in CRXDE and enter the value of the
jcr:primaryTypeinto Fusion. In this example, the value of NY_FairHealth.pdf isdam:Asset.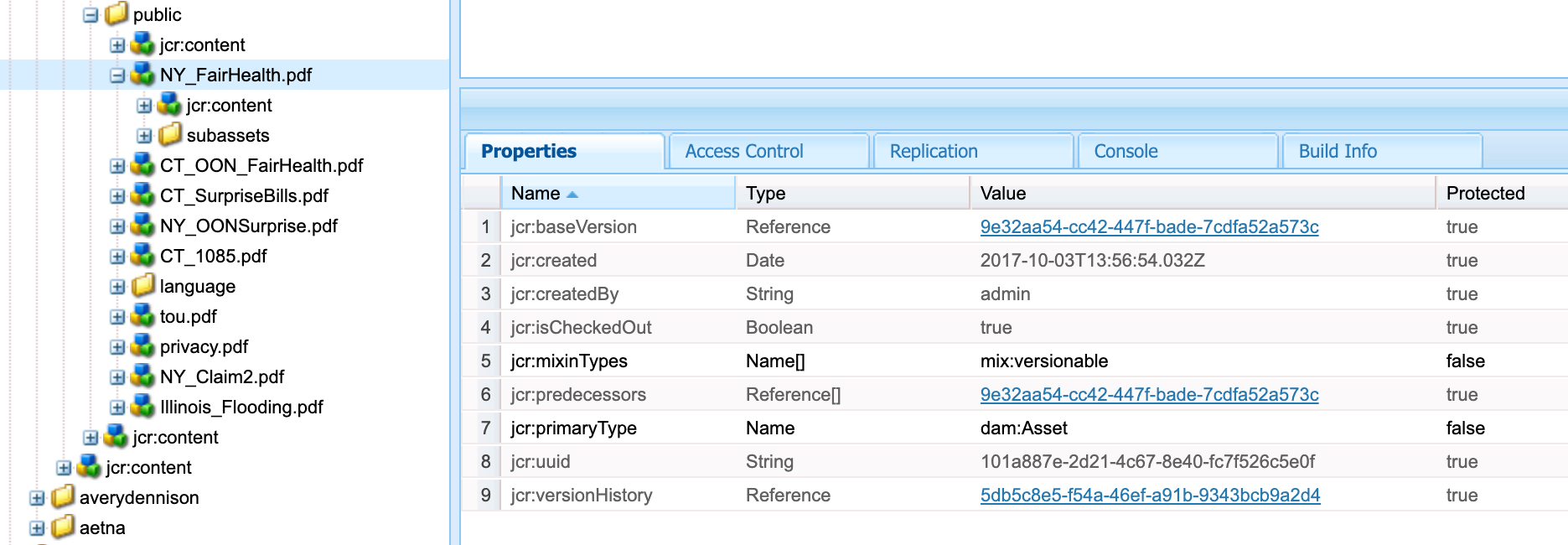
-
You can choose which content properties to include and exclude from the index. These parameter values are represented by Java regex. For example, to only include properties that start with “jcr” enter
jcr:(.*). -
In Fusion, click Save when you’re done configuring the AEM datasource.
Configuration settings
| Setting | Notes |
|---|---|
AEM URL |
Required. This is the URL used to access the AEM Admin UI. |
AEM Username |
Required. The user should have sufficient permissions to read content paths and access Users/Group APIs in case Security Trimming is needed. |
AEM Password |
Required. |
Page Batch Size |
Number of documents to fetch per page request. A higher value can increase crawling speed but also increases memory usage. |
Thread wait (ms) |
Number of milliseconds to wait between fetch requests. This property can be used to throttle a crawl if necessary. |
Paths to search |
Required. |
Paths that should not be fetched |
Java regex for paths that should not be fetched. |
AEM Types |
Required. AEM document type |
Attachment types |
File extensions to index. |
Content Property Include Regexes |
A list of regex strings of content properties to include in indexed documents. Example: |
Content Property Exlude Regexes |
A list of regex strings of content properties to exclude from indexed documents. Example: |
Enable Security Trimming |
Enable this setting for content filtering of results based on the user’s id passed in during query. |
Group Mappings |
AEM user groups mapped to indexed values in the security trimming field which are used to filter content based on user id passed in query. |
Cache Expire Time (m) |
Specifies how long a query is cached in minutes. |
Field data population
There are multiple sources where AEM data is indexed. The /bin/querybuilder.json endpoint data is mandatory and must exist in order for a document to be indexed.
Note the list of fields that can appear in an indexed document:
| Field | Source | Comments |
|---|---|---|
|
|
Field: path |
|
|
Whole data in text format. |
|
|
All top level fields of JSON object. |
|
|
Used if path ends with one of |
|
|
Used if there is no |
|
|
Defaults to |
|
|
Populated in case of attachment/link. |
|
File extension of the path. |
Populated in case of attachment/link. |
|
|
|
|
|
|