JDBC SQL V2 Connector
The JDBC SQL V2 connector uses a Java-based API to fetch documents from a relational database.
For configuration details, see JDBC V2 Connector Configuration Reference.
Supported JDBC drivers
This section contains a list of supported JDBC drivers that are compatible with any driver/database that implements a SQL standard.
Authentication parameters may be provided as part of the connection string. It is not necessary to include a username and password in the datasource configuration.
MySQL
-
Default driver class name: com.mysql.cj.jdbc.Driver
-
For example:
jdbc:mysql://mysql:3306/testdb
Postgresql
-
Default driver class name: org.postgresql.Driver
-
For example:
jdbc:postgresql://postgres:5432/testdb
Microsoft SQL Server and Azure SQL Service
-
Default driver class name: com.microsoft.sqlserver.jdbc.SQLServerDriver
-
For example:
jdbc:sqlserver://mssql:1433 -
Also used for cloud-based Azure SQL Service
For example:
jdbc:sqlserver://azure-test.database.windows.net:1433;database=testdbencrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;
Oracle database
-
Default driver class name: oracle.jdbc.OracleDriver
-
For example:
jdbc:oracle:thin:@oracledb:1521:orc1
IBM DB2
-
Default driver class name: com.ibm.db2.jcc.DB2Driver
-
For example:
jjdbc:db2://db2:50000/testdb
Crawl
The JDBC V2 connector retrieves data based on the user-supplied SQL query. The SQL implementation allows full use of all features, but for best results, structure the SQL query to utilize pagination.
Special variables for pagination
Use the following properties to specify pagination:
-
${limit} -
${offset}
The properties are:
-
Placeholders that the connector updates based on batchSize
-
Used in native SQL as values for the LIMIT and OFFSET parameters, respectively.
Examples of SQL statements that include the properties for:
-
MySQL, postgresql, and DB2:
SELECT * FROM example_table LIMIT ${limit} OFFSET ${offset} -
Microsoft, Azure, and Oracle:
SELECT * FROM example_table ORDER BY id OFFSET ${offset} ROWS FETCH NEXT ${limit} ROWS ONLY
Nested queries
The connector supports nested queries, which:
-
Are a set of SQL queries performed on each row returned by the main query
-
Can degrade performance significantly because they are executed on every row returned
Use the `${id}` variable to retrieve items associated with a specific primary key. For example:
SELECT * FROM example_table ORDER BY id OFFSET ${offset} ROWS FETCH NEXT ${limit} ROWS ONLY
Incremental crawl
In addition to the main SQL query, users can also specify an optional delta SQL query that returns only new and modified items to increase performance during recrawls. The special ${limit} and ${offset} pagination variables are the same as in normal crawls.
Special incremental crawl variable
Use the ${last_index_time} variable for an incremental crawl, which is:
-
A placeholder that contains the time the last crawl completed
-
Used to filter results for items added or modified since the last time the datasource job was run
-
Stored as a timestamp in the following format:
yyyy-MM-dd HH:mm:ss.SSS
| The format may not be compatible with all driver date math implementations without additional conversion steps. |
An example of a SQL statement that includes the ${last_index_time} property is:
SELECT * FROM example_table WHERE (timestamp_column >= ${last_index_time})
Stray content deletion
Stray content deletion is:
-
A plug-in feature that deletes documents from a content collection that are not rediscovered on subsequent crawls after the first crawl. This process is also referred to as removing stale documents from the content collection.
-
Enabled by default
-
Configured by the user because native SQL does not provide the ability to retrieve rows that have been deleted from a table
| Using a delta query to perform incremental crawling only returns new and modified items. If stray content deletion is enabled when the delta query is run, unmodified items that are still valid are deleted. |
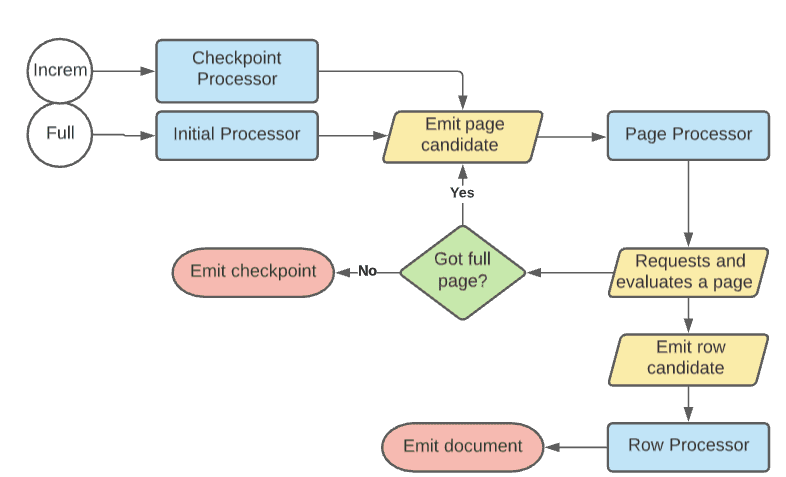
Processor flow diagram
The diagram represents the flow for full crawls.
NOTE: Incremental crawls are the same except they begin with the Checkpoint Processor, which emits a page candidate with the:
-
Delta SQL query if provided
-
Original query if the delta query is not provided