Fusion Concepts and Components
Basic Fusion concepts are explained below. Since the core of Fusion Server is Solr, you may also find it useful to familiarize yourself with Solr terminology.
Apps
Fusion apps provide tailored search functionality to specific groups of users.
An app is a named set of linked objects, including collections, datasources, index and query pipelines, index and query profiles, parsers, and more. Using roles and security realms, you can define security on a per-app basis.
Collections
Collections consist of stored data and the datasources that determine how the data is ingested and indexed. Collections are a way to logically group your data sets. Fusion’s concept of collections is the same as Solr collections. See Collection Management.
Datasources
Datasources are the configurations that determine how data is ingested and indexed. Each datasource includes a connector configuration, a parser configuration, and an index pipeline configuration. See Datasource Configuration.
Connectors
Connectors are the conduit between Fusion and your external data sources. Connectors retrieve your data and import it into Fusion Server.
See the Connectors Reference Guide for a complete list of available connectors.
Parsers
Parsers interpret incoming data in order to determine its format and fields. A parser consists of a sequence of parsing stages, each designed to parse a different data format, sometimes recursively. See the Parser Stages Reference Guide for complete details about all available parsing stages.
Index pipelines
Index pipelines format the incoming raw data into fielded documents that it can be indexed and searched by the Solr core. A pipeline consists of a sequence of stages, and each stage performs a different kind of processing based on user-configured logic. See the Index Pipeline Stages Reference Guide for a complete list of available index pipeline stages.
Query Pipelines
Query pipelines manipulate incoming queries and return an ordered list of matching results from Solr. Individual search results are called documents. See Query Pipeline Configuration.
Fusion Components
Apache Solr
Solr is the search platform that powers Fusion. There are multiple aspects to Fusion’s use of Solr:
-
Fusion components manage Solr search and indexing and provide analytics over these collections. Fusion’s analytics components depend on aggregations over information which is stored in a Solr collection.
-
Fusion collections are all Solr collections.
-
Application data is stored as one or more Solr collections.
-
Fusion’s own logs are stored as Solr collections.
-
A few Fusion service APIs use Solr as a backing store, notably Parameter Sets.
Solr configuration
Fusion requires that Solr run with SolrCloud enabled.
Configuration for Solr’s Web service is in https://FUSION_HOST:FUSION_PORT/apps/jetty/solr.
Solr logs
Solr log files are in https://FUSION_HOST:FUSION_PORT/var/log/solr.
Accessing the Solr UI
With Fusion installed out of the box, you can still access the Solr UI at http://localhost:8983/solr/.
Solr documentation
Solr documentation and additional resources are available at http://lucene.apache.org/solr/resources.html.
Apache Spark
Apache Spark is a fast and general execution engine for large-scale data processing jobs that can be decomposed into stepwise tasks which are distributed across a cluster of networked computers. Spark provides faster processing and better fault-tolerance than previous MapReduce implementations.
The following schematic shows the Spark components available from Fusion:
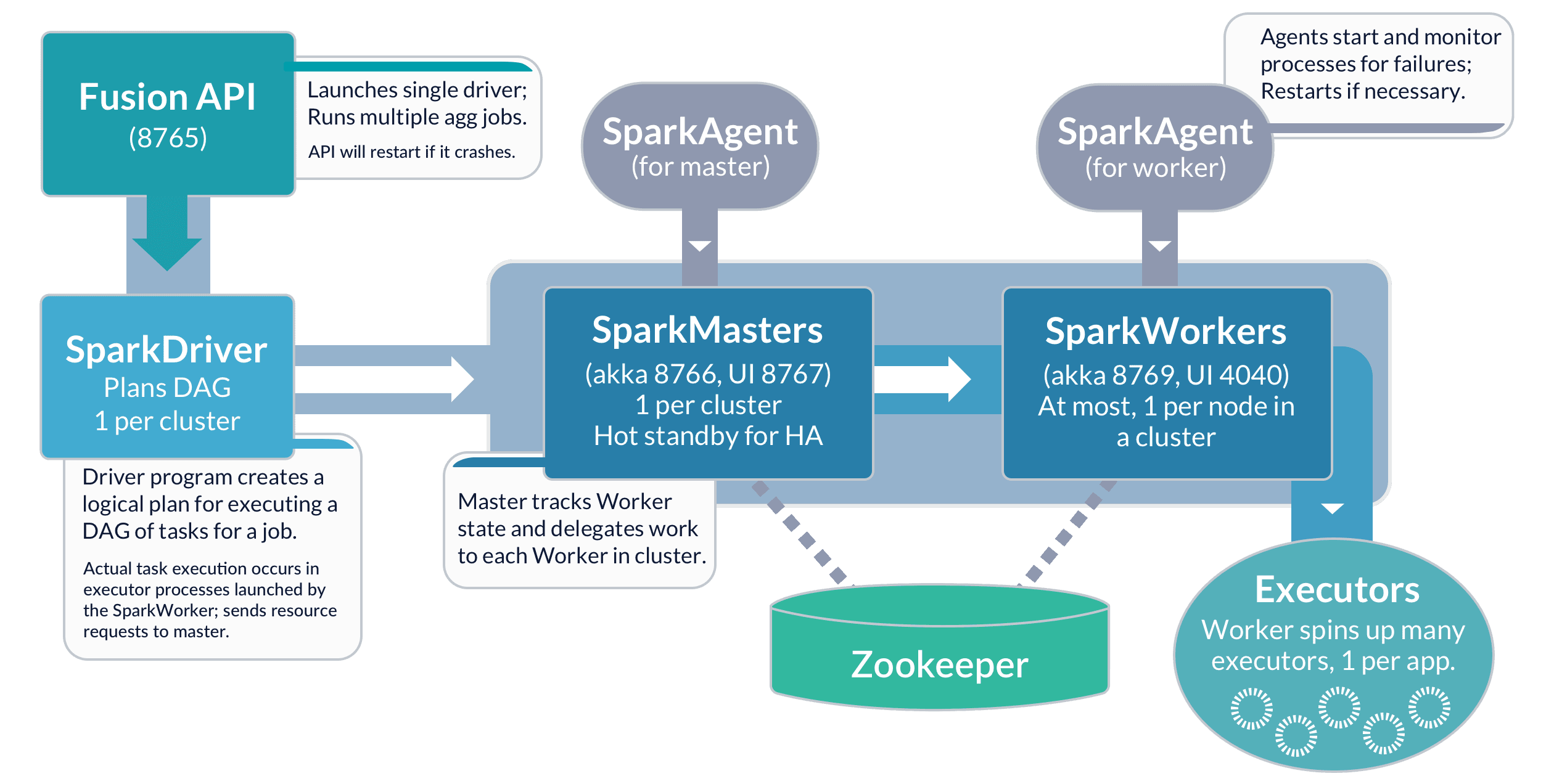
See Spark Administration for more information.
Apache ZooKeeper
Apache ZooKeeper is a distributed configuration service, synchronization service, and naming registry.
Fusion uses ZooKeeper to configure and manage all Fusion components in a single Fusion deployment, therefore a ZooKeeper service must always be running as part of the Fusion deployment. For high availability, this should be an external 3-node ZooKeeper cluster. All Fusion Java components communicate with ZooKeeper using the ZooKeeper API.
For ZooKeeper installation instructions, see the ZooKeeper documentation.
You can find ZooKeeper’s logs at https://FUSION_HOST:FUSION_PORT/var/log/zookeeper.
ZooKeeper Terminology
-
znode. ZooKeeper data is organized into a hierarchal name space of data nodes called znodes. A znode can have data associated with it as well as child znodes. The data in a znode is stored in a binary format, but it is possible to import, export, and view this information as JSON data. Paths to znodes are always expressed as canonical, absolute, slash-separated paths; there are no relative reference.
-
ephemeral nodes. An ephemeral node is a znode which exists only for the duration of an active session. When the session ends the znode is deleted. An ephemeral znode cannot have children.
-
server. A ZooKeeper service consists of one or more machines; each machine is a server which runs in its own JVM and listens on its own set of ports. For testing, you can run several ZooKeeper servers at once on a single workstation by configuring the ports for each server.
-
quorum. A quorum is a set of ZooKeeper servers. It must be an odd number. For most deployments, only 3 servers are required.
-
client. A client is any host or process which uses a ZooKeeper service.
See the official ZooKeeper documentation for details about using and managing a ZooKeeper service.
Fusion ZooKeeper Nodes
Fusion configuration data is stored in ZooKeeper under two znodes:
-
Node
lucidstores all application-specific configurations, including collection, datasource, pipeline, signals, aggregations, and associated scheduling, jobs, and metrics. -
Node
lucid-apollo-adminstores all access control information, including all users, groups, roles, and realms.
The Solr Admin tool provides a ZooKeeper node browser tool. In the case of the Fusion default developer deployment, the Fusion runs scripts are configured to run the instances of both Solr and ZooKeeper which are included with the Fusion distribution, and therefore we take a fresh installation of a Fusion developer instance and use the embedded Solr’s Admin tool to explore how Fusion’s configurations are managed in ZooKeeper.
On initial install, the "lucid" znode contains the set of default configurations used by Fusion’s services:
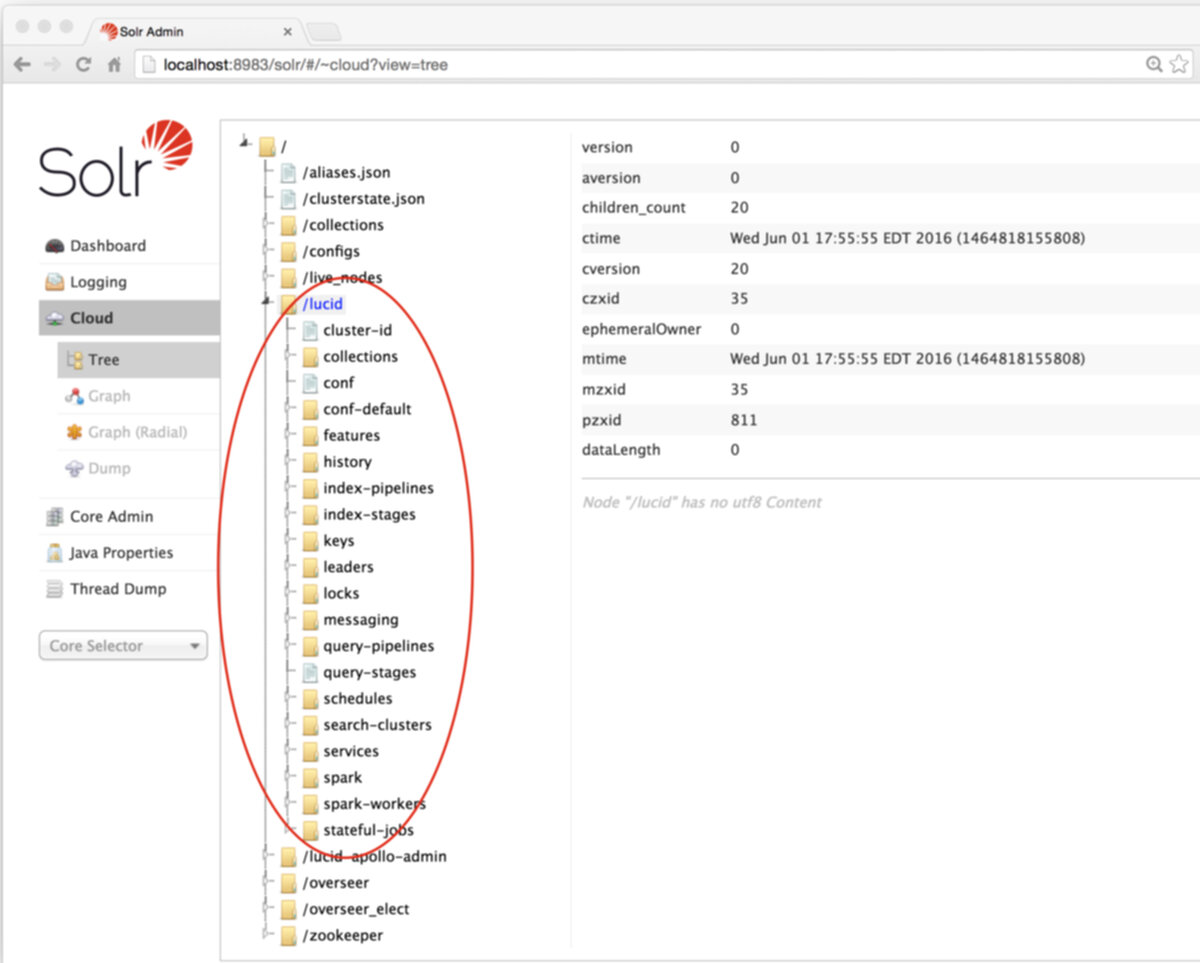
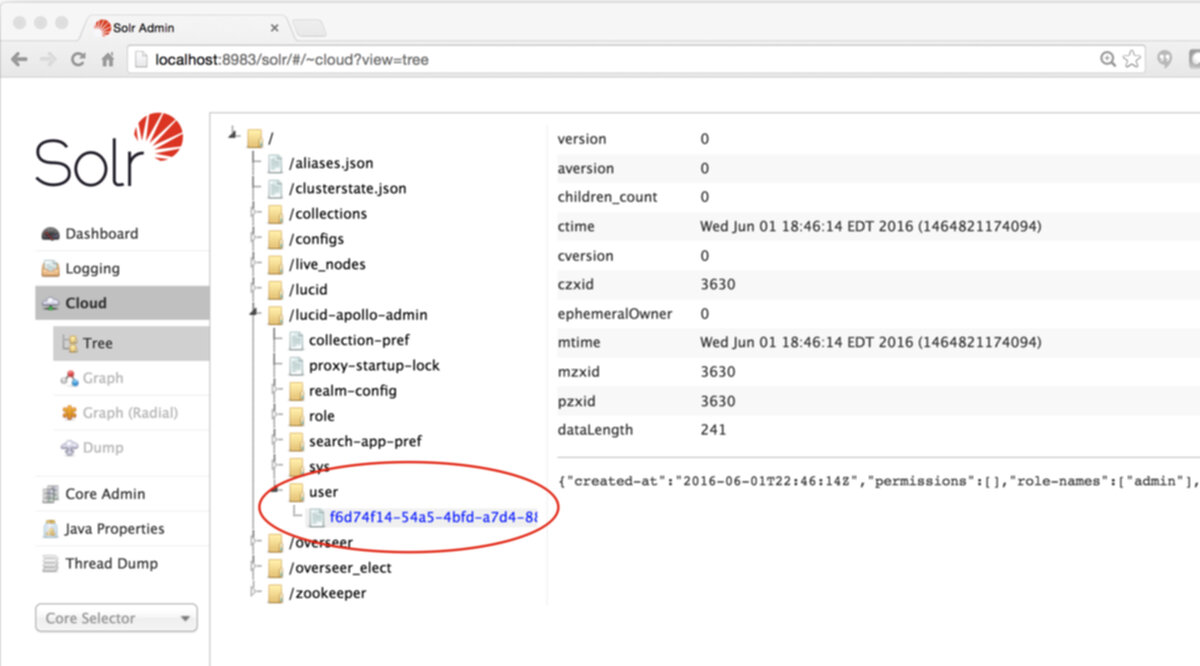
The "lucid-apollo-admin" znode contains the set of nodes used by Fusion’s access control services:
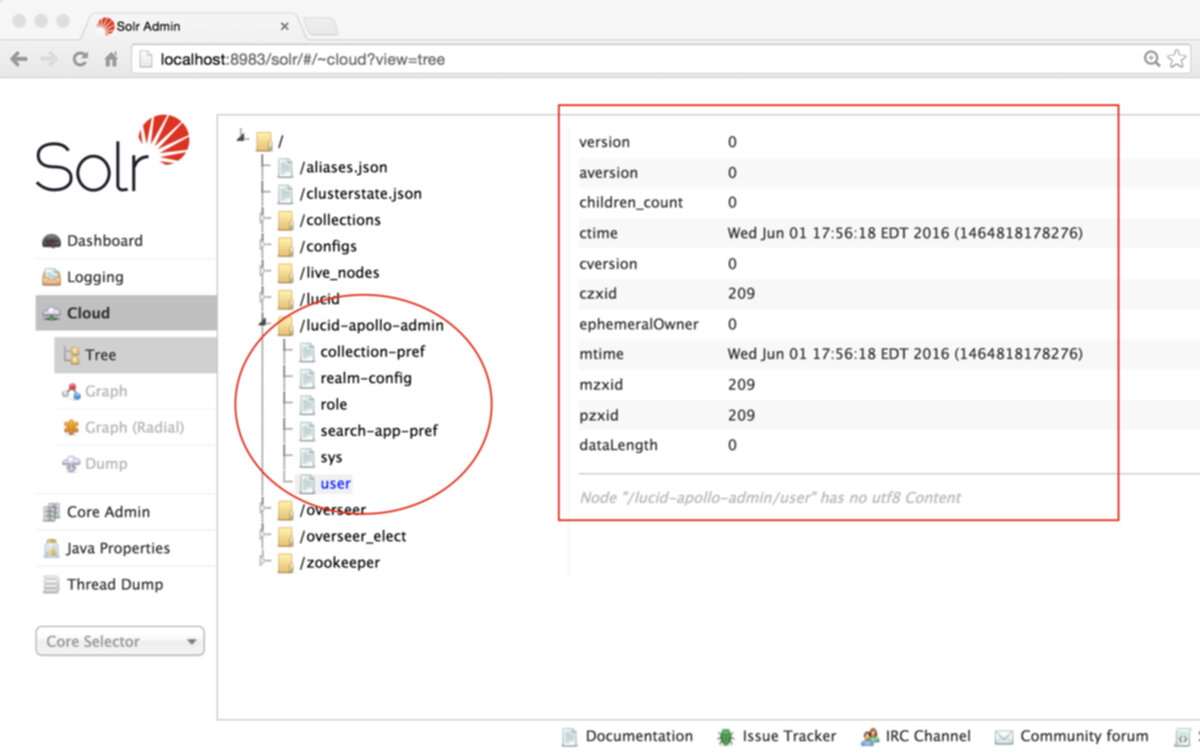
In the above screenshot, the ZooKeeper node browser is browsing the contents of znode "lucid-apollo-admin/users" which is empty. The Fusion distribution ships without any user accounts. The initial user added to Fusion is the Fusion native realm "admin" user. This entry is only created on initial startup via the Fusion UI "set admin password" panel. Once you submit the admin password, the admin user account is created. Until Fusion contains as least the admin user account, you cannot use the system, because all Fusion requests require proper authorization.
Once the admin password is set, and you have created one or more Fusion collections and have populated them by running one or more datasources, these collections, datasources, pipelines, and other application configuration settings are stored under the "lucid" znode:
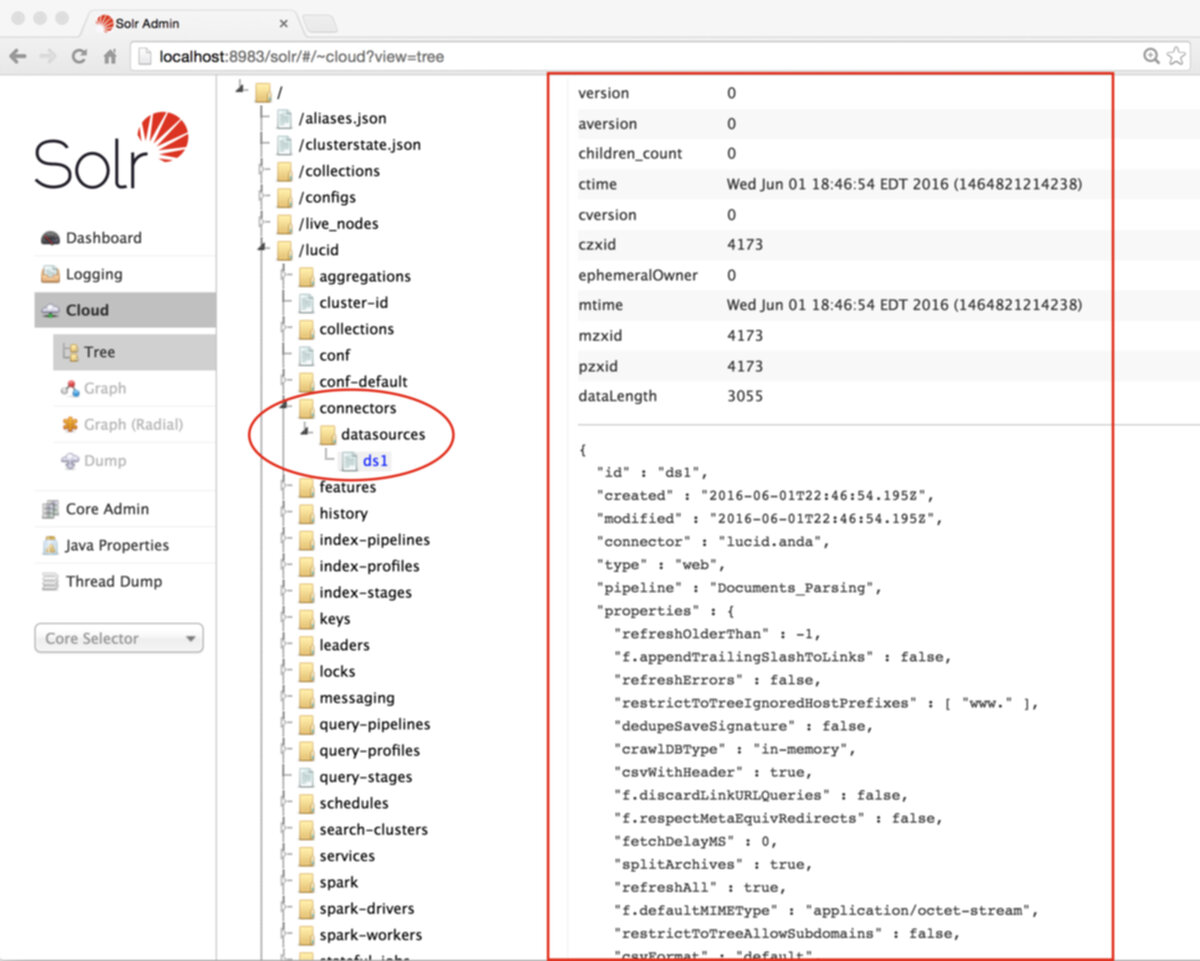
In the above screenshot, the ZooKeeper node browser is browsing the contents of znode "lucid/connectors/datasources/ds1". This datasource was used to populate a Fusion collection with documents retrieved via a webcrawl. Note that in the initial screenshot for znode "lucid", there is no "connectors" node at all.
The "lucid-apollo-admin" znode now contains one user accounts for user "admin":
Jetty
Jetty provides Web services for Fusion’s UI, APIs, and Connectors, plus Solr. Each of those components runs inside its own instance of Jetty, using a separate configuration. Configurations for each component are located in https://FUSION_HOST:FUSION_PORT/apps/jetty.
Securing Fusion using SSL requires configuring Jetty to use SSL. For example, to secure the UI you need to modify the configuration in https://FUSION_HOST:FUSION_PORT/apps/jetty/admin-ui.
See SSL Security (Unix) or SSL Security (Windows).
Log messages about Jetty are written to the log files for the components that use it:
-
https://FUSION_HOST:FUSION_PORT/var/log/ui -
https://FUSION_HOST:FUSION_PORT/var/log/api -
https://FUSION_HOST:FUSION_PORT/var/log/connectors -
https://FUSION_HOST:FUSION_PORT/var/log/solr