Fusion 5.2.0
Release date: August 24, 2020
Component versions:
| Component | Version |
|---|---|
Solr |
8.4.1 |
ZooKeeper |
3.5.7 |
Spark |
2.4.5 |
Kubernetes |
GKE, AKS, EKS 1.18 Rancher (RKE) and OpenShift 4 compatible with Kubernetes 1.18 OpenStack and customized Kubernetes installs not supported. See Kubernetes support for end of support dates. |
Ingress Controllers |
Nginx, Ambassador (Envoy), GKE Ingress Controller Istio not supported. |
More information about support dates can be found at Lucidworks Fusion Product Lifecycle.
|
Looking to upgrade?
Check out the Fusion 5 Upgrades topic for details. |
New Features
Fusion
Fusion DSL
| The beta release of Fusion Domain Specific Language (DSL) functions are available beginning with Fusion 5.2.2. |
Fusion Domain Specific Language (DSL) provides expected search results as a JSON response in a way that reduces search query complexity for the user.
Previously, users needed to understand complex syntax to express certain search queries in Fusion (for example, the best way to express a facet filter). DSL gives Fusion control over how to execute a query by transforming a structured query input into a Solr request, where we can add intelligence around the index and the user’s intent.
Why Search DSL
Fusion Search Domain Specific Language (DSL) reduces search query complexity for the user. Fusion Search DSL supports expressive search queries and responses via a structured, modern JSON format.
Search DSL is an alternative to the current (now referred to as) “Legacy” format for performing search queries. Previously, users needed to understand complex syntax to express certain search queries in Fusion (for example, the best way to express a facet filter).
Compared to the legacy Solr parameter format, Search DSL is structured to more closely align with the central concepts of Fusion and provide a more usable alternative for expressing complex Fusion queries.
Search DSL gives Fusion control over how to execute a query by transforming a structured query input into a Solr request, at which time Fusion can add intelligence around the index and the user’s intent.
Limitations
Despite the advantages, there are still some important limitations to be aware of when deciding whether to use the Fusion Search DSL.
| These limitations only apply to DSL queries. Legacy queries can still be issued separately from DSL queries without being subject to these limitations. |
-
Head / Tail Rewrite. Support is currently limited when using DSL queries:
-
In order to work on DSL queries, the
Improved Querymust be entered in as a JSON string representing the desiredmainquery that should be issued (this replaces thequeryDefinition.mainfield in the rewritten DSL query) -
The query rewrites produced by the built-in head/tail rewrite job will NOT work on DSL queries, as the job only outputs legacy-style rewrites
-
-
Query Stage Support. All query stages are fully supported
-
Rules Support. All kinds of rules are fully supported with the exceptions noted below
-
Set Params. Not supported
-
Custom Rule. Not supported
-
See Domain Specific Language for additional information, including examples.
Pipeline Stage and Blob Editor
Fusion 5.2.0 introduces the ability to create and copy pipeline stages by pasting JSON objects in the Fusion UI. Additionally, it allows users to edit certain blobs in a similar fashion. Only JSON is supported, and JSON validation is included to prevent the user from saving an invalid object.
You can copy and paste pipeline stage JSON data directly from the Fusion UI by clicking the JSON View button in the stage’s configuration panel.
Existing stages are READ-ONLY and have the option to Copy only.
New stages will have Copy and Paste buttons. Changes are applied to the stage with the Apply button.
| Users will still need to Save the stage for the changes made in the editor to be saved. |
This allows you to quickly and easily duplicate and edit stages within your app or share your configurations with others.
See Index Pipeline Stages and Query Pipeline Stages for more information. For instructions, see Use the Pipeline Stage JSON Editor.
The blobs editor is accessed by clicking the Edit blob button in the blobs configuration panel:
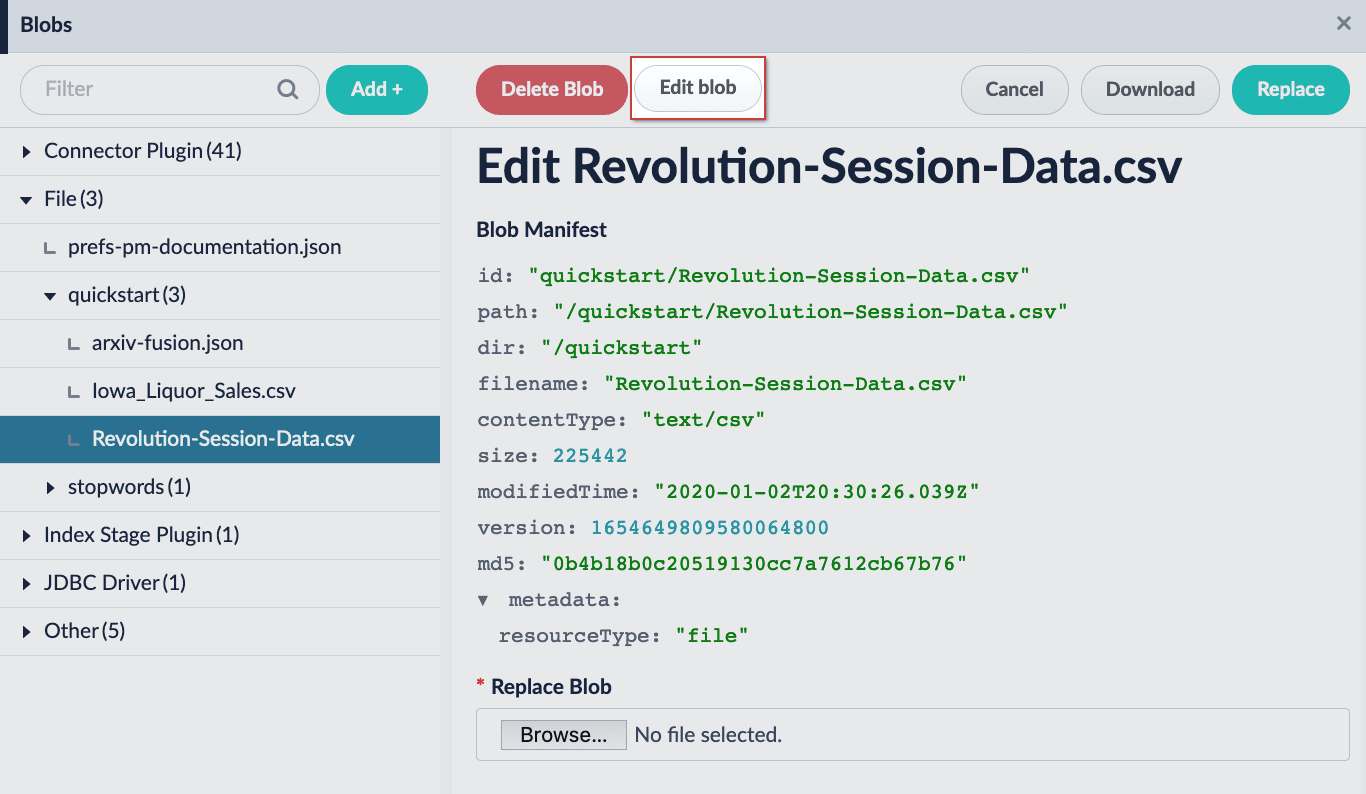
The blobs editor is similar to the pipeline stage editor with the following exceptions:
-
Multiple file types are supported, including:
-
CSV
-
Java
-
JavaScript
-
Python
-
SCALA
-
Typescript
-
Plain text
-
-
Existing blobs are not considered READ-ONLY, giving users the option to edit existing blobs.
-
When the user clicks the Save button, changes to the blob data take effect immediately.
See Blob Storage for more information. For instructions, see Use the Blob Editor.
Highlight Query Pipeline Stage
Fusion 5.2.0 introduces a new query pipeline stage, Highlight.
The Highlight stage allows you to highlight key parts of fields by generating snippets and appending match tags to the highlighted terms. The highlight match tags can then be styled in your web search application.
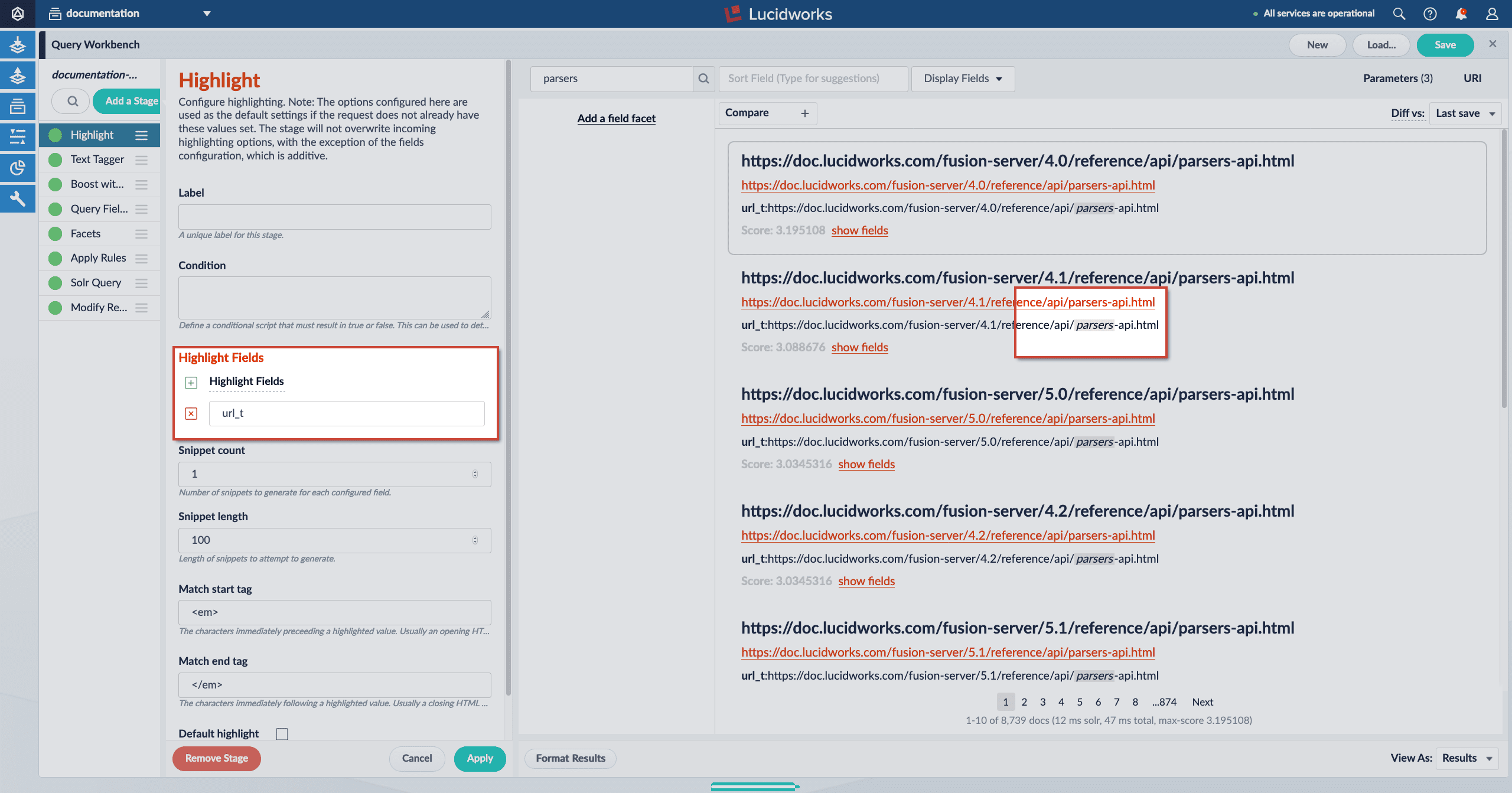
To learn more, including how this stage differs from other highlighting options, see the Highlight Stage reference article. To learn how to use the Highlight stage, see Configure the Highlight Query Pipeline Stage.
Fusion
-
The new Classification job analyzes how existing documents are categorized and produces a model that can be used to predict the categories of new documents at index time.
-
The new BPR Recommender job produces better signals-based recommendation data with a shorter running time than the ALS Recommender job (deprecated in this release).
-
The new Content-Based Recommender job analyzes similarities in your content to provide recommendations when you do not have enough signals data for signals-based recommendation methods.
-
The new Query-to-Query Session-Based Similarity job provides improved query-to-query recommendations using a two-pronged approach.
-
A new Recommend Similar Queries query pipeline stage was added to support the new query-to-query recommendations job.
Predictive Merchandiser
Templates
The Templates screen in the Rules Editor allows you to design, test, and implement a wide variety of search experiences. Results are conditionally delivered from multiple different query pipelines, enabling you to use Fusion’s search, browse, and AI-driven functionality throughout your site.
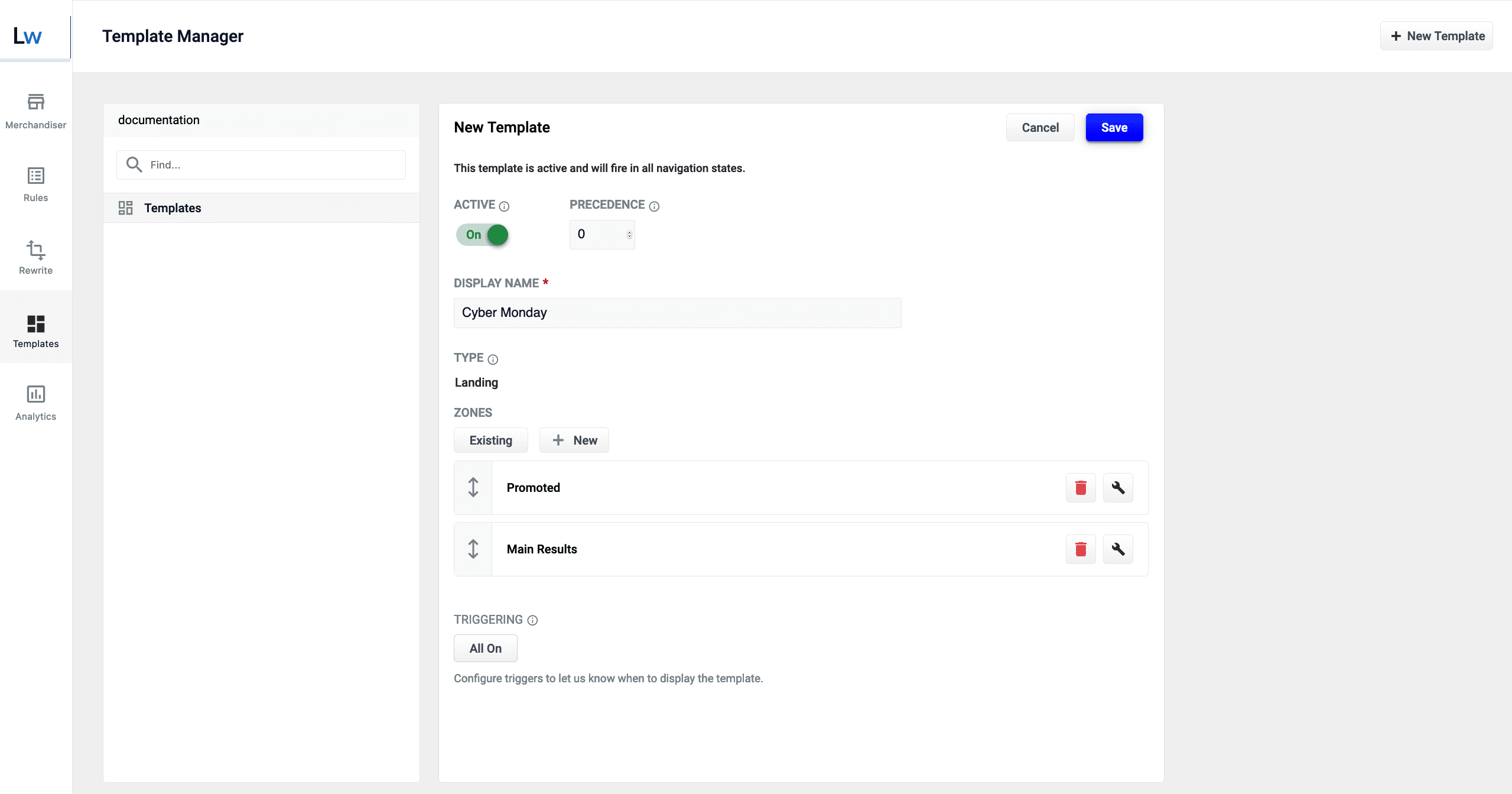
See Predictive Merchandiser Templates for more information. For instructions on how to use Templates, see Use Predictive Merchandiser Templates.
Improvements
Fusion
-
Fusion SQL adds search and math expressions to the SQL experience, with new, intuitive, easy-to-learn functions that simplify the way power users query Fusion to explore unstructured text and patterns in data. In this release you can combine structured and unstructured data stored in Solr to understand numeric distributions and correlations, fit models, explore clusters, perform powerful sampling, use text analyzers for entity extraction, find significant terms, and perform time series analysis.
Learn more about Fusion SQL or explore the new functions for these features:
-
You can now download connectors directly from the Fusion UI. Powered by the Connector Plugins Repository API, you can easily view which connectors are available to you and download new connectors with a single click. Navigate to Indexing > Datasources, click Add, and click the name of the connector you want to install:
-
The Field Facet query pipeline stage now allows users to specify Field facet threads:
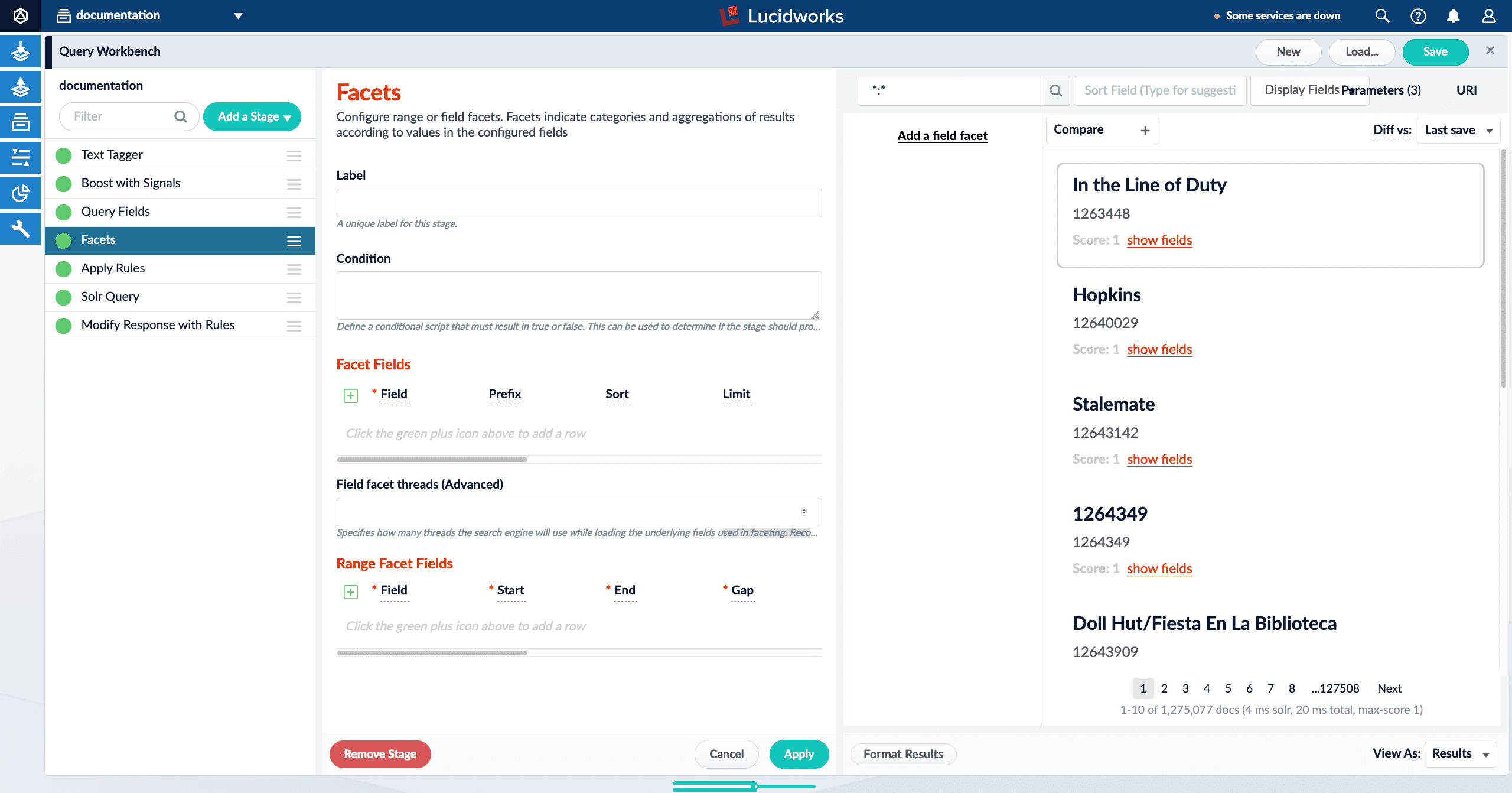
Specifies how many threads the search engine will use while loading the underlying fields used in faceting. Recommended that this is kept at 0 or blank, which means the data is loaded in the thread already running the query.
-
Various Spark jobs improvements:
-
Improved logging
-
All Spark writing operations now support
min-output-partitions -
SQL aggregation Jobs are audited for natural key usage
-
Recommender aggregation
-
-
Previously, the Apache Pulsar client automatically blocked message objects if the queue was full. Now, this behavior is configurable as a boolean value. By default, this is set to
falsein the query service to ensure errors are successfully logged even if the Pulsar service becomes available. Outside of the query service, the default istrue.
-
Pulsar is updated to version 2.6.0.
-
The Query Workbench no longer displays additional pages if there are not enough results to populate those pages.
-
The Query Workbench now displays error messages instead of writing error messages to the console only.
-
AsyncJoinQueryStageis updated to always produce an error message to improve debugging.
-
You can now configure your realm with additional headers to check for allowed IPs. This is useful when your gateway is behind a proxy which is replacing the incoming IP.
-
A new Index Stage SDK API method is added:
{{Document.allFields()}}. This method returns all document fields, including internal fields. (Internal fields start with the{{lw}}prefix.)
Fusion
-
Solr’s
zkhostis now included in the Jupyter environment. It no longer needs to be explicitly defined for each Jupyter notebook.
-
You can now use more than 30 parameters in a single business rule.
Predictive Merchandiser
-
Publishing performance is significantly improved.
Other changes
Fusion
-
Pipeline context can now properly serialize/deserialize arbitrary values and nested maps/lists when sent via Pulsar Message.
-
The Pulsar default namespace is now set when creating or updating an index pipeline or profile. Previously, this was set when the stage was first enacted.
-
All paths starting with
/apolloare removed.
-
Miscellaneous UI improvements.
-
The Rules Editor’s Dashboard is renamed to Analytics.
Predictive Merchandiser
-
Enabled the ability to use nonexistent fields and values when creating a rule.
-
Miscellaneous UI improvements.
Bug fixes
Fusion
-
Fixed a bug which sometimes prevented indexing of access control items at the end of a connector job.
-
The AD ACL V2 connector now uses the
group.membersfield instead ofuser.memberOf. This addresses a change in Windows Server 2019 that caused incremental crawls to fail.
-
Fixed a bug that prevented Prometheus metrics from generating for connectors.
-
Fixed a bug that sometimes prevented job status icons from updating.
-
Fixed a bug with the job service that sometimes resulted in certain error conditions to create multiple, redundant method calls.
-
Fixed a bug that prevented Spark executors from receiving the Prometheus pushgateway address.
Fusion
-
Fixed a bug that sometimes caused the Document Clustering job to fail if a
trainingDataFilterQuerywas used.
Predictive Merchandiser
-
Fixed a bug that prevented item-for-item recommendations from displaying in the Details panel.
-
Fixed a bug that prevented facet names from appearing in Predictive Merchandiser if the facets were created in a query pipeline using the Field Facet stage.
-
Fixed a bug that caused errors in the Predictive Merchandiser UI when switching between query profiles with grouping in use and query profiles without.
-
Fixed a bug that prevented a
set-paramsrule from saving successfully multiple parameters are defined.
Deprecations
-
The config-sync Fusion microservice was deprecated and removed. It is no longer available in any release of Fusion, including Fusion 5.2.
| The following features and functionalities are deprecated in Fusion 5.2.0 and will be removed in a future release. |
-
The Blob Store’s searchable aspects
-
MLeap in Machine Learning models
-
MLeap deployments of SpaCy and SparkNLP in favor of Seldon Core deployments
Your Seldon Core deployments will continue to work in Fusion 5.2.0+. -
Various Fusion jobs:
-
Query-to-Query Collaborative Similarity Job
We recommend the use of the Query-to-Query Session-Based Similarity jobs, which provides better performance and query coverage. -
We recommend the use of the experimental BPR Recommender job, which provides better results with a shorter running time. The ALS Recommender job will be removed completely when the BPR Recommender job goes General Availability (GA). -
Logistic Regression Classifier Training Jobs and Random Forest Classifier Training Jobs
We recommend the use of the new Classification job, which provides more options and better logging.
-
-
Various Fusion pipeline stages:
These stages are deprecated in favor of new forthcoming Seldon Core functionality. These stages will be removed when the replacements are in General Availability (GA).
Removals
| The following features and functionalities are removed in Fusion 5.2.0. |
-
Various Fusion jobs:
-
Co-occurrence Similarity Jobs
-
Collection Analysis Jobs
-
Item Similarity Recommender Jobs
-
Legacy Item Recommender Jobs
-
Legacy Item Similarity Jobs
-
Levenshtein Spell Checking Jobs
-
Matrix Decomposition-Based Query-Query Similarity Jobs
-
SQL-Based Experiment Metric Jobs
-
Statistically Interesting Phrases Jobs
-
Known Issues
Connectors
-
Requests with the headless browser in the user agent are rejected. This issue is fixed in Fusion 5.4.2.
-
The SharePoint connector does not apply lowercasing to incoming records. This issue is fixed in Fusion 5.4.
Signals
-
The Send click signals function does not populate signals collections. This issue is fixed in Fusion 5.2.1 and 5.3.
-
Training on the BPR recommendation job when metadata settings are specified will fail.
Workaround Steps:
-
Download the shell script from here.
-
Run the script in a terminal
./rec-5.2.0-workflow-fix.sh <namespace>Replace <namespace>with the k8s namespace where Fusion is deployed.
-
-
Running the recommendation or classification workflows may result in pods failing with a docker image pull error.
Workaround Steps:
-
Download the shell script.
-
Run the scrupt in a terminal
./workflow-5.2.0-tag-fix.sh <namespace>Replace <namespace>with the k8s namespace where Fusion is deployed.
-