Recommendations
Signals contain data about how users interact with search results. Once your Fusion app has accumulated a sufficient number of aggregated signals, they become useful for automatically producing recommendations and boosts for better relevance and higher conversion rates.
The same data used to produce recommendations can also be used for automatic boosting. So although recommendations and boosts are different (as explained below), these topics use "recommender data" to refer to the data that can be used for boosting as well as for recommendations.
Recommendations vs boosts
Recommendations and boosts are two ways of presenting AI-powered estimations about which items are most likely to interest a user:
| Recommendations | Boosts |
|---|---|
Personalized search results from a special, automatic query, whether or not the user has performed a query. Recommendations can be based on a variety of criteria, as in the examples below:
|
Modifications to the scores of the items in a query’s search results. The set of search results does not change, but their ranking does. For example:
Boosts can also be configured manually, using the Query Workbench or the Query Rewriting UI. You can also perform boosts within a set of recommendations. |
These topics explain how to configure and use recommendations and boosts:
-
Getting Started shows you how to quickly enable the basic feature set and see some results.
-
Recommendation Methods explains the available approaches to recommendations and boosting, including methods that do not rely on signals.
Recommendations data flow
The diagram below shows the flow of data between the default objects created when you enable recommendations. You can create additional object for different recommendation methods.
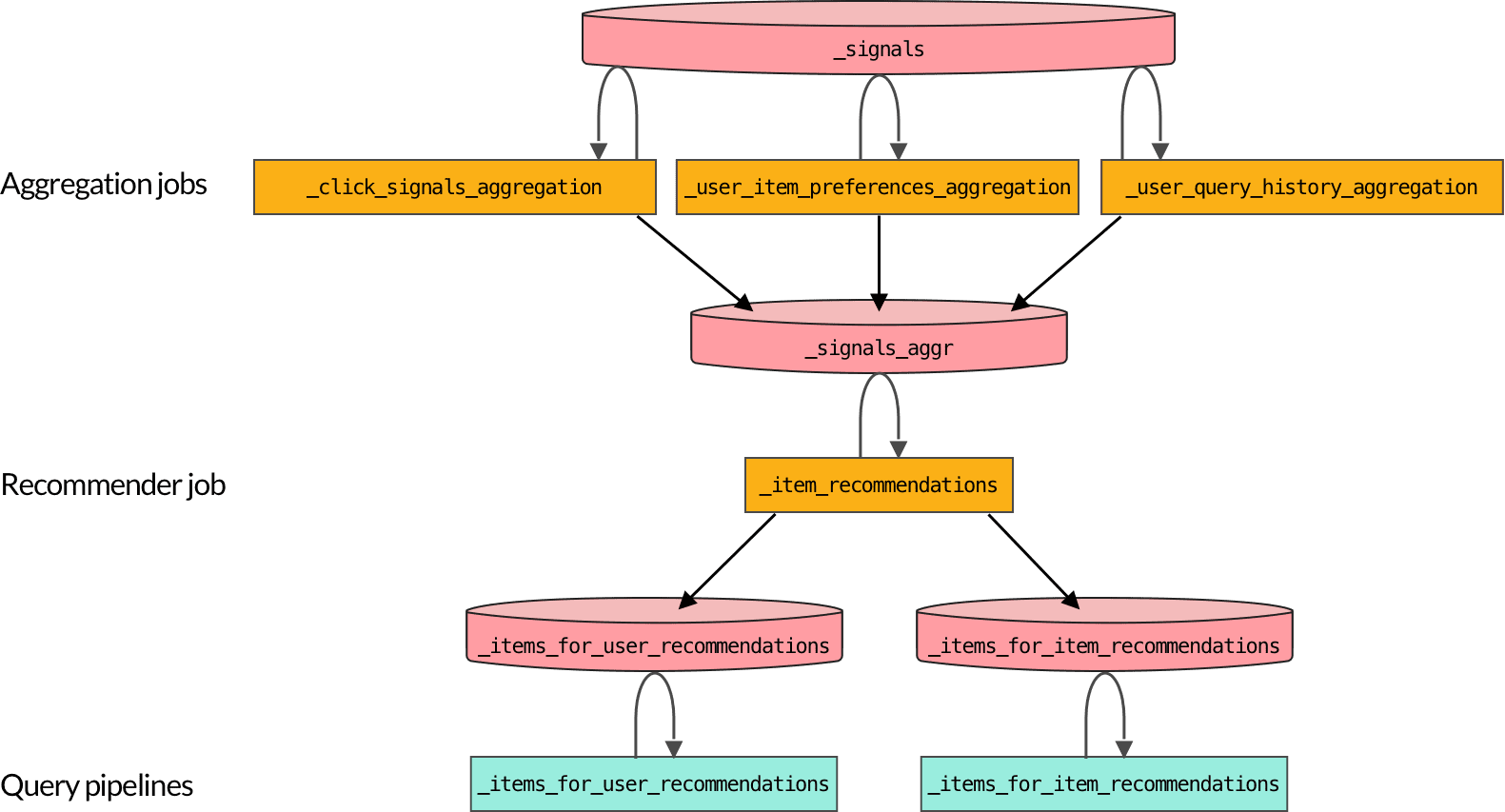
-
Signals data is aggregated into a format that can be consumed by recommender jobs.
Your search application should be sending well-formed signals data to Fusion whenever there is user activity on your site.
By default, the
COLLECTION_NAME_click_signals_aggregationjob runs every 15 minutes while the_user_item_preferences_aggregationand_user_query_history_aggregationjobs run once per day.You can use signals data for boosting, without enabling recommendations, using the Boost with Signals query pipeline stage. The default query pipeline includes this stage.
-
Recommender data is produced when recommender jobs analyze aggregated signals.
The default
COLLECTION_NAME_item_recommendationsjob must be manually scheduled or run on demand. Make sure that theCOLLECTION_NAME_user_item_preferences_aggregationjob runs first. -
Query pipelines retrieve recommender data to produce recommendations and boosts.
When recommendations are enabled, Fusion creates two query pipelines for recommendations:
COLLECTION_NAME_items_for_user_recommendationsCOLLECTION_NAME_items_for_item_recommendations
Recommendations storage requirements
Collaborative recommendations are derived from data generated by Fusion jobs and stored in special collections. You can estimate the required storage for this data if you know the following:
-
the number of unique users in the signals collection (
num_users)To find the number of unique values of the
user_idfield, navigate to Analytics > App Insights > Analytics > Users. The Number of Distinct Data Values panel displays the number of unique users: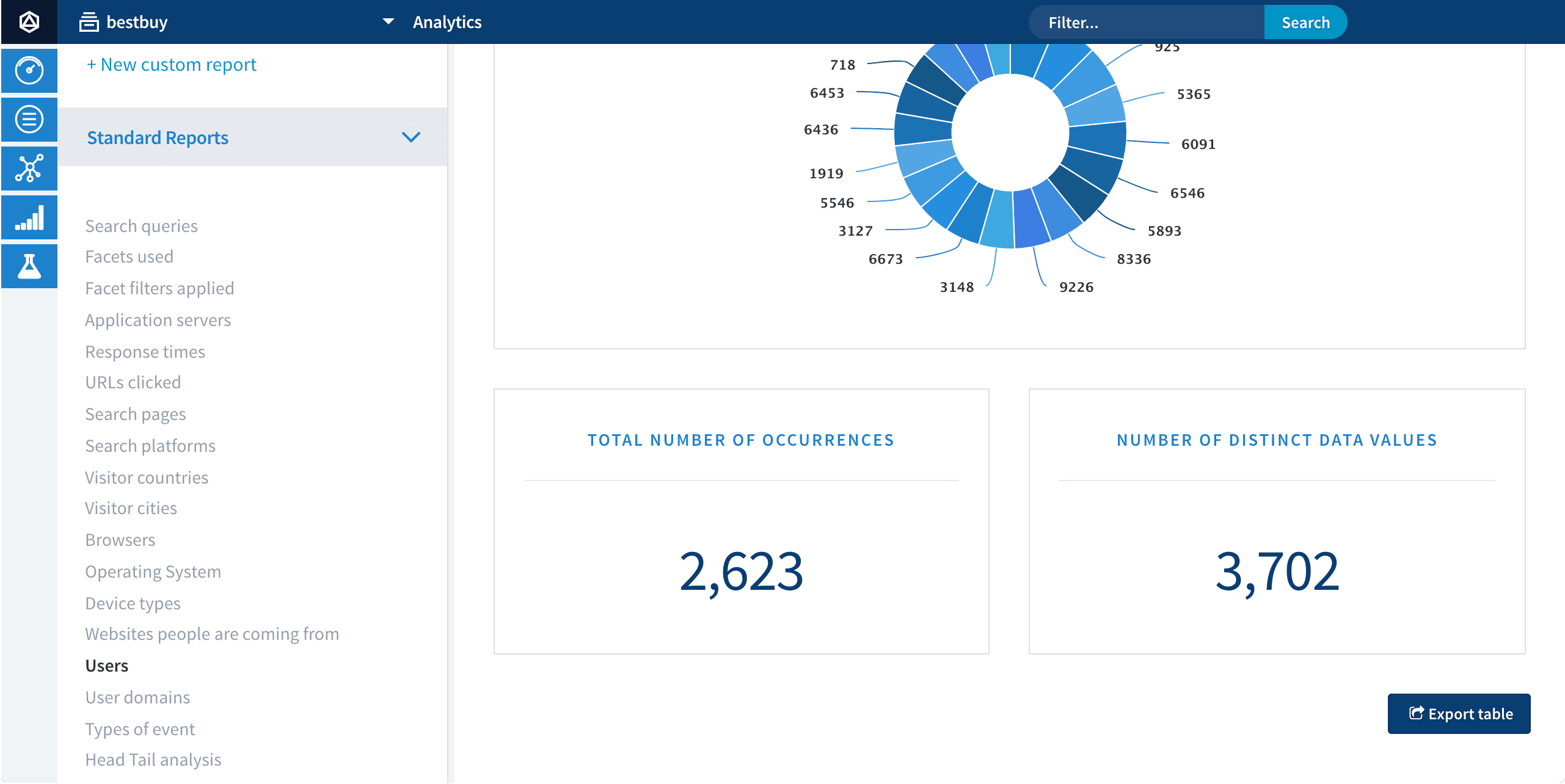
If no value is displayed here or the value is not accurate, see Important fields for signals to verify that your signals data is well-formed.
-
the number of unique items in the main collection (
num_items)Navigate to Collections > Collections Manager to see the total number of documents in your main collection.
-
the number of recommendations to be computed per user (
num_recs_per_user)This is a configuration parameter in the recommender job, with a default value of 10.
-
the number of item similarities to be computed per item (
num_item_sims)This is a configuration parameter in the recommender job, with a default value of 10.
Every time the recommender job runs, this many new recommender documents are created:
num_users * num_recs_per_user + num_items * num_item_simsEach of these documents is about 300 bytes. This is the minimum size; they can be larger if you configure the recommender job to pull item metadata fields from the main collection for inclusion in recommender documents. These fields are useful when displaying recommendations in your front-end search application.
| In your recommender jobs, verify that Delete Old Recommendations is selected so that only the latest recommender data is stored. |
Additional resources
-
View our training on Recommendations.