Install a Fusion 4.x Cluster (Unix)
This article describes how to install a Fusion cluster on multiple Unix nodes. Instructions are given for each of the cluster arrangements described in Deployment Types.
Preliminary steps
Before proceeding to one of the sections that follow, perform these steps:
-
Prepare your firewall so that the Fusion nodes can communicate with each other. The default ports list contains a list of all ports used by Fusion. From this list, it is important that the ZooKeeper ports, Apache Ignite ports, and the Spark ports (if you are using Spark) are open between the different nodes for cross-cluster communication.
-
Fusion for Unix is distributed as a compressed archive file (
.tar.gz). Move this file to each node that will run Fusion.To leverage the copies of Solr and/or ZooKeeper that are distributed with Fusion on nodes that will not run Fusion (as a simple means of obtaining compatible versions of the other software), also download the Fusion compressed archive file to each of those nodes. Below, you will edit configuration files so that Fusion does not run on those nodes. -
On each node, change your working directory to the directory in which you placed the Fusion tar/zip file and unpack the archive, for example:
$ cd /opt/lucidworks $ tar -xf fusion-version.x.tar.gz
Failures in the Fusion install or startup may occur if the Fusion installation directory name contains a space. The resulting directory is named
https://FUSION_HOST:FUSION_PORT. You can rename this if you wish. This directory is considered your Fusion home directory. See Directories, files, and ports for the contents of thehttps://FUSION_HOST:FUSION_PORTdirectory.
| In the sections that follow, for every step on multiple nodes, complete the step on all nodes before going to the next step. It is especially important that you do not start Fusion on any node until the instructions say to do so. |
In the steps below, the port numbers reflect default port numbers and one common choice (port 2181 for nodes in an external ZooKeeper cluster). Port numbers for your nodes might differ.
Nodes running core Fusion services and Solr also run ZooKeeper
In this cluster arrangement, a ZooKeeper cluster runs on the same nodes that run core Fusion services and Solr.
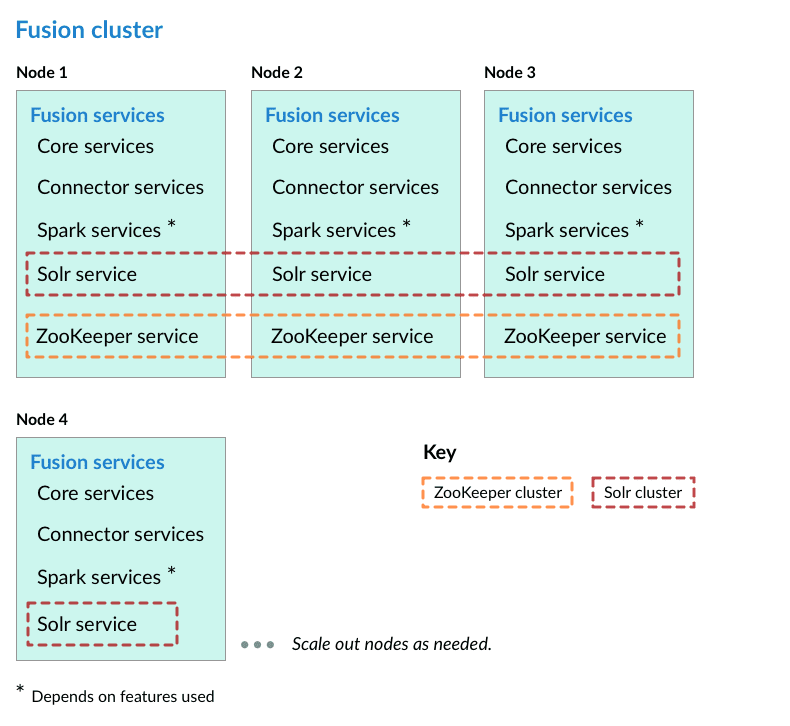
Perform the steps in the section Preliminary steps, and then perform these steps:
-
Assign a number to each Fusion node, starting at 1. We refer to the number we assign to each node as the ZooKeeper myid.
-
On each Fusion node, create a
https://FUSION_HOST:FUSION_PORT/data/zookeeperdirectory, and a file calledmyidin that directory. Edit the file and save the ZooKeeper myid assigned for this node as the only contents. -
On each Fusion node, open the
https://FUSION_HOST:FUSION_PORT/conf/zookeeper/zoo.cfgfile in a text editor and add the following after theclientPortline (change the hostnames or IP addresses to the correct ones for your servers):server.1=[Hostname or IP for ZooKeeper with myid 1]:2888:3888 server.2=[Hostname or IP for ZooKeeper with myid 2]:2888:3888 server.3=[Hostname or IP for ZooKeeper with myid 3]:2888:3888
For example:
server.1=10.10.31.130:2888:3888 server.2=10.10.31.178:2888:3888 server.3=10.10.31.166:2888:3888
Do not use localhost or 127.0.0.1 as the hostname/IP. Specify the hostname/IP that other nodes will use when communicating with the current node.
|
-
On each Fusion node, edit
default.zk.connectinhttps://FUSION_HOST:FUSION_PORT/conf/fusion.cors(fusion.propertiesin Fusion 4.x) to point to the ZooKeeper hosts:default.zk.connect=[ZK host 1]:9983,[ZK host 2]:9983,[ZK host 3]:9983 -
On each node, start ZooKeeper with
bin/zookeeper start. Zookeeper should start without errors. If a ZooKeeper instance fails to start, check the log athttps://FUSION_HOST:FUSION_PORT/var/log/zookeeper/zookeeper.log. -
On each node, start the rest of Fusion using
bin/fusion start. -
Create an admin password and log in to Fusion at
http://FIRST_NODE_IP:8764, whereFIRST_NODE_IPis the IP address of your first Fusion node. -
Verify the Solr cluster is healthy by looking at
http://ANY_NODE_IP:8983/solr/#/~cloud, whereANY_NODE_IPis the IP address of a Solr node. All of the nodes should appear green. -
If necessary, prepare high availability by setting up a load balancer in front of Fusion so that it load balances between the Fusion UI URL’s at
http://NODE_IP:8764.Consult your load balancer’s documentation for instructions.
Nodes running ZooKeeper are not running core Fusion services or Solr
In this cluster arrangement, the ZooKeeper cluster runs on nodes in the Fusion cluster on which core Fusion services and Solr are not running.
Each node in the Fusion cluster has Fusion and Solr installed. ZooKeeper runs on Fusion cluster nodes on which neither Fusion nor Solr is running.
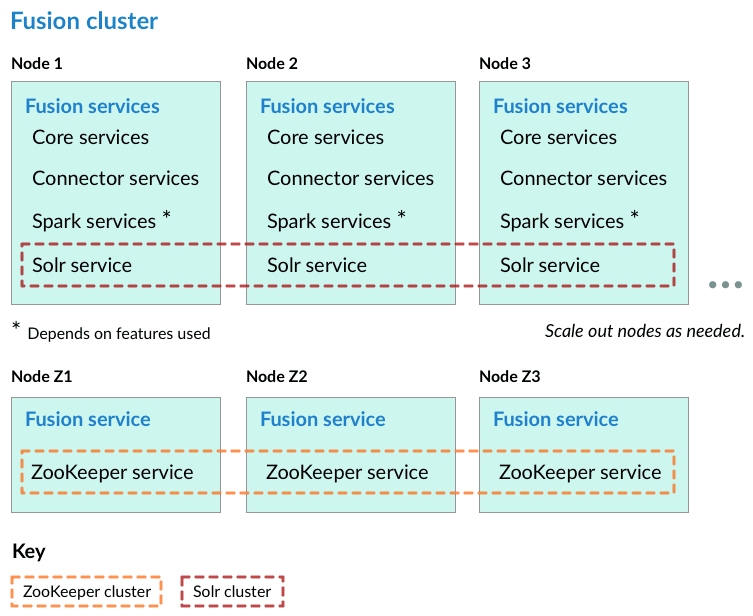
Perform the steps in the section Preliminary steps, and then perform these steps:
-
Assign a number to each Fusion node, starting at 1. We refer to the number we assign to each node as the ZooKeeper myid.
-
On each Fusion node, create a
fusion\latest.x\data\zookeeperdirectory, and a file calledmyidin that directory. Edit the file and save the ZooKeeper myid assigned for this node as the only contents. -
On each Fusion node, open the
fusion\latest.x\conf\zookeeper\zoo.cfgfile in a text editor and add the following after theclientPortline (change the hostnames or IP addresses to the correct ones for your servers):server.1=[Hostname or IP for ZooKeeper with myid 1]:2888:3888 server.2=[Hostname or IP for ZooKeeper with myid 2]:2888:3888 server.3=[Hostname or IP for ZooKeeper with myid 3]:2888:3888
For example:
server.1=10.10.31.130:2888:3888 server.2=10.10.31.178:2888:3888 server.3=10.10.31.166:2888:3888
-
Edit
conf/fusion.cors(fusion.propertiesin Fusion 4.x) and removezookeeperfrom thegroup.defaultlist. This will make it so that ZooKeeper does not start when you start Fusion. -
On each Fusion node, edit
default.zk.connectinhttps://FUSION_HOST:FUSION_PORT/conf/fusion.cors(fusion.propertiesin Fusion 4.x) to point to the ZooKeeper hosts:
default.zk.connect=[ZK host 1]:2181,[ZK host 2]:2181,[ZK host 3]:2181
-
On each node, start ZooKeeper with
bin/zookeeper start. Zookeeper should start without errors. If a ZooKeeper instance fails to start, check the log athttps://FUSION_HOST:FUSION_PORT/var/log/zookeeper/zookeeper.log. -
On each node, start the rest of Fusion using
bin/fusion start. -
Create an admin password and log in to Fusion at
http://FIRST_NODE_IP:8764, whereFIRST_NODE_IPis the IP address of your first Fusion node. -
Verify the Solr cluster is healthy by looking at
http://ANY_NODE_IP:8983/solr/#/~cloud, whereANY_NODE_IPis the IP address of a Solr node. All of the nodes should appear green. -
If necessary, prepare high availability by setting up a load balancer in front of Fusion so that it load balances between the Fusion UI URL’s at
http://NODE_IP:8764.Consult your load balancer’s documentation for instructions.
Known issues
Metrics collection failure
When the Java virtual machine (JVM) is started, the /tmp/.java_pid<pid> file is created and is the socket used:
-
To attach a debugger
-
By the agent to connect to the service that collects Java Management Extension (JMX) metrics
A known issue in Java 8 is that the timestamp is not updated, which causes the file to be deleted in standard Linux distribution systems. For example, the /tmp/.java_pid<pid> is deleted after ten days on a standard Amazon Linux in EC2.
When the JVM code the agent uses cannot locate the file, then it:
-
Sends a
-QUITmessage to the JVM -
Triggers a thread dump to be printed to standard out
The standard out:
-
Is logged to the agent log
-
Generates the "No metrics can be gathered" exception
-
Prints a complete thread dump
-
Sends the thread dump to system logs
Choose one of the two workarounds:
-
Exclude the
agent.logfrom the logstash configuration. The logshipping is turned off for the file. The disadvantage to this option is that the metrics are missing. -
Change the cron job in the Linux distribution that deletes the
/tmpfiles older than "x" days to exclude deleting the/tmp/.java_pid<pid>files. If your system is running the Linux Systemd software suite on EC2, the setting is typically located in theusr/lib/tmpfiles.d/tmp.conffile. For Dial On Demand (DOD), remove the call that configures the JMX Metrics requirement for the debugger attachment to the Java service.