Spark Configuration for Fusion 4.x
Spark has a number of configuration properties. In this section, we will cover some of the key settings you will need to use Fusion’s Spark integration.
For the full set of Fusion’s spark-related configuration properties, see the Spark Jobs API.
Spark master/worker resource allocation
| If you co-locate Spark workers and Solr nodes on the same server, then be sure to reserve some CPU for Solr to avoid a compute intensive Spark job from starving Solr of CPU resources. |
Number of cores allocated
To change the CPU usage per worker, you need to use the Fusion configuration API to update this setting, as in the following example.
curl -u USERNAME:PASSWORD -H 'Content-type:application/json' -X PUT -d '6' \
http://localhost:8764/api/configurations/fusion.spark.worker.coresYou can also over-allocate cores to a spark-worker, which usually is recommended for hyper-threaded cores by setting the property spark-worker.envVars to SPARK_WORKER_CORES=<number of cores> in the fusion.cors (fusion.properties in Fusion 4.x) file on all nodes hosting a spark-worker. For example, a r4.2xlarge instance in EC2 has 8 CPU cores, but the following configuration will improve utilization and performance:
spark-worker.envVars=SPARK_WORKER_CORES=16,SPARK_SCALA_VERSION=2.11,SPARK_PUBLIC_DNS=${default.address},SPARK_LOCAL_IP=${default.address}
You can obtain the IP address that the Spark master web UI binds to with this API command:
curl http://localhost:8765/api/v1/spark/master
We encourage you to set the default.address property in fusion.cors (fusion.properties in Fusion 4.x) to ensure that all Spark processes have a consistent address to bind to.
|
After making this change to your Spark worker nodes, you must restart the spark-worker process on each.
On Unix:
./spark-worker restart
Give this command from the bin directory below the Fusion home directory, for example, /opt/fusion/latest.x.
On Windows:
spark-worker.cmd restart
Give this command from the bin directory below the Fusion home directory, for example, C:\lucidworks\fusion\latest.x.
Memory allocation
The amount of memory allocated to each worker process is controlled by Fusion property
fusion.spark.worker.memory which specifies the total amount of memory available for all executors spun up by that Spark Worker process. This is the quantity seen in the memory column against a worker entry in the Workers table.
The JVM memory setting (-Xmx) for the spark-worker process configured in the fusion.cors (fusion.properties in Fusion 4.x) file controls how much memory the spark-worker needs to manage executors (and not how much memory should be made available to your job(s)). When modifying the -Xmx value, use curl as follows:
curl -u USERNAME:PASSWORD -H 'Content-type:application/json' -X PUT -d '8g' \
http://localhost:8764/api/configurations/fusion.spark.worker.memory| Typically, 512m to 1g is sufficient for the spark-worker JVM process. |
The Spark worker process manages executors for multiple jobs running concurrently.
For certain types of aggregation jobs you can also configure the per executor memory, but this can impact how many jobs you can run concurrently in your cluster.
Unless explicitly specified using the parameter spark.executor.memory, Fusion calculates the amount of memory that can be allocated to the executor
Aggregation Spark jobs always get half the memory of the amount assigned to the workers.
This is controlled by the fusion.spark.executor.memory.fraction property, which is set to 0.5 by default.
For example, Spark workers have 4 Gb of memory by default and the executors for aggregator Spark jobs are assigned 2 Gb for each executor.
To let Fusion aggregation jobs use more of the memory of the workers, increase fusion.spark.executor.memory.fraction property to 1.
Use this property instead of the Spark executor memory property.
curl -u USERNAME:PASSWORD -H 'Content-type:application/json' -X PUT -d '1' \
http://localhost:8764/api/configurations/fusion.spark.executor.memory.fractionAfter making these changes and restarting the workers, when we run a Fusion job, we get the following:
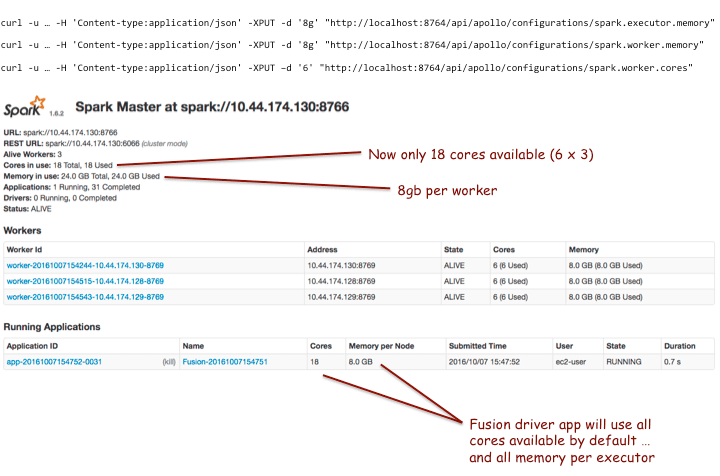
Cores per driver allocation
The configuration property fusion.spark.cores.fraction lets you limit the number of cores used by the Fusion driver applications (default and scripted). For example, in the screenshot above, we see 18 total CPUs available.
We set the cores fraction property to 0.5 via the following command:
curl -u USERNAME:PASSWORD -H 'Content-type:application/json' -X PUT -d '0.5' \
http://localhost:8764/api/configurations/fusion.spark.cores.fractionThis cuts the number of available cores in half, as shown in the following screenshot:

Ports used by Spark in Fusion
This table lists the default port numbers used by Spark processes in Fusion.
| Port number | Process |
|---|---|
4040 |
SparkContext web UI |
7337 |
Shuffle port for Apache Spark worker |
8600-8616 (Fusion 4.0.x only.) |
Akka ports used between Spark driver, master, workers, and API |
8767 |
Spark master web UI |
8770 |
Spark worker web UI |
8766 |
Spark master listening port |
8769 |
Spark worker listening port |
8772 ( |
Spark driver listening port |
8788 ( |
Spark BlockManager port |
If a port is not available, Spark uses the next available port by adding 1 to the assigned port number.
For example, if 4040 is not available, Spark uses 4041 (if available, or 4042, and so forth).
Ensure that the ports in the above table are accessible, as well as a range of up to 16 subsequent ports. For example, open ports 8772 through 8787, and 8788 through 8804, because a single node can have more than one Spark driver and Spark BlockManager.
Spark-related directories and files in Fusion
The following directories and files are for Spark components and logs in Fusion.
Spark components
These directories and files are for Spark components:
| Path (relative to Fusion home) | Notes |
|---|---|
|
Script to manage ( |
|
Script to manage ( |
|
Script to manage ( |
|
Wrapper script to launch the interactive Spark shell with the Spark Master URL and shaded JAR |
|
Apache Spark distribution; contains all JAR files needed to run Spark in Fusion |
|
Hadoop home directory used by Spark jobs running in Fusion |
|
Add custom JAR files to this directory to include in all Spark jobs |
|
JAR files used to construct the classpath for the |
|
Working directory for the |
|
Working directory for the |
|
Temporary work directories are created in when an application is running. They are removed after the driver is shut down or closed. |
|
Working directory for the SQL service |
|
The shaded JAR built by the API service; contains all classes needed to run Fusion Spark jobs. If one of the jars in the Fusion API has changed, then a new shaded jar is created with an updated name. |
Spark logs
These directories and files are for configuring and storing Spark logs:
| Path (relative to Fusion home) | Notes |
|---|---|
Log configuration |
|
|
Log configuration file for the |
|
Log configuration file for the |
|
Log configuration file for the Spark Driver application launched by Fusion; this file controls the log settings for most Spark jobs run by Fusion |
(Fusion 4.1+ only.) |
Log configuration file for custom script jobs and Parallel Bulk Loader (PBL) based jobs |
|
Log configuration file for jobs built using the Spark Job Workbench |
|
Log configuration file for Spark executors; log messages are sent to STDOUT and can be viewed from the Spark UI |
|
Log configuration file for the Fusion SQL service |
Logs |
|
|
Logs for the |
|
Logs for the |
|
Logs for the |
|
Main log file for built-in Fusion Spark jobs |
|
Main log file for custom script jobs |
|
Main log file for custom jobs built using the Spark Job Workbench |
Connection configurations for an SSL-enabled Solr cluster
You will need to set these Java system properties used by SolrJ:
-
javax.net.ssl.trustStore -
javax.net.ssl.trustStorePassword -
javax.net.ssl.trustStoreType
For the following Spark configuration properties:
-
spark.executor.extraJavaOptions -
fusion.spark.driver.jvmArgs -
spark.driver.extraJavaOptions
> curl -H 'Content-type:application/json' -X PUT \ -d '-Djavax.net.ssl.trustStore=/opt/app/jobs/ssl/solrtrust.jks -Djavax.net.ssl.trustStorePassword=changeit -Djavax.net.ssl.trustStoreType=jks' \ "http://localhost:8764/api/configurations/spark.executor.extraJavaOptions" > curl -H 'Content-type:application/json' -X PUT \ -d '-Djavax.net.ssl.trustStore=/opt/app/jobs/ssl/solrtrust.jks -Djavax.net.ssl.trustStorePassword=changeit -Djavax.net.ssl.trustStoreType=jks' \ "http://localhost:8764/api/configurations/fusion.spark.driver.jvmArgs" > curl -H 'Content-type:application/json' -X PUT \ -d '-Djavax.net.ssl.trustStore=/opt/app/jobs/ssl/solrtrust.jks -Djavax.net.ssl.trustStorePassword=changeit -Djavax.net.ssl.trustStoreType=jks' \ "http://localhost:8764/api/configurations/spark.driver.extraJavaOptions"