Automatically Classify New Documents at Index Time
You can predict the categories of new documents at index time by using the Classification job to analyze previously-classified documents in your index and produce a training model, then referencing the model in the Machine Learning index stage.
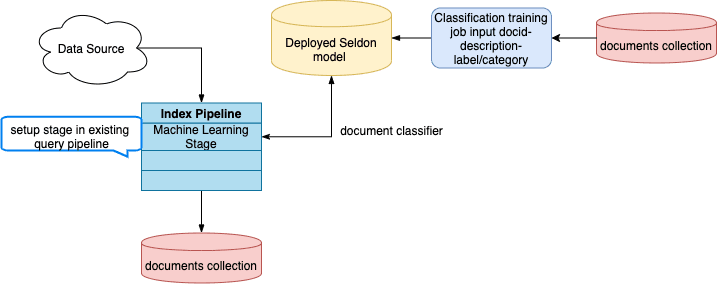
How to configure new document classification
-
Navigate to Collections > Jobs > Add+ > Classification to create a new Classification job.
-
Configure the job as follows:
-
In the Model Deployment Name field, enter an ID for the new classification model.
-
In the Training Data Path field, enter the collection name or cloud storage path where your main content is stored.
-
In the Training Data Format field, leave the default
solrvalue if the Training Data Path is a collection. Otherwise, specify the format of your data in cloud storage. -
In the Training collection content field, enter the name of the field that contains the content to analyze.
The content field that you choose depends on your use case and the types of queries that your users commonly make.
For example, you could choose the description field if users tend to make descriptive queries like "4k TV" or "soft waterproof jacket". But if users are more likely to search for specific brands or products, such as "LG TV" or "North Face jacket", then the product name field might be more suitable.
-
In the Training collection class field, enter the name of the field that contains the category data.
For additional configuration details, see Best practices below.
-
-
Save the job.
-
Specify the model’s name in the Machine Learning stage of your index pipeline.
-
In the Model input transformation script field, enter the following:
/* Name of the document field to feed into the model. */ var documentFeatureField = "body_t" /* Model input construction. */ var modelInput = new java.util.HashMap() modelInput.put("text", doc.getFirstFieldValue(documentFeatureField)) modelInput -
In the Model output transformation script field, enter the following:
// In case if top_k_predictions are needed var top1ClassField = "top_1_class_s" var top1ScoreField = "top_1_score_d" var topKClassesField = "top_k_classes_ss" var topKScoresField = "top_k_scores_ds" var jsonOutput = JSON.parse(modelOutput.get("_rawJsonResponse")) var parsedOutput = {}; for (var i=0; i<jsonOutput["names"].length;i++){ parsedOutput[jsonOutput["names"][i]] = jsonOutput["ndarray"][i] } doc.addField(top1ClassField, parsedOutput["top_1_class"][0]) doc.addField(top1ScoreField, parsedOutput["top_1_score"][0]) if ("top_k_classes" in parsedOutput) { doc.addField(topKClassesField, new java.util.ArrayList(parsedOutput["top_k_classes"][0])) doc.addField(topKScoresField, new java.util.ArrayList(parsedOutput["top_k_scores"][0])) }-
Click Apply.
-
-
Save the query pipeline.
Custom output transformation script example
var top1ClassField = "top_1_class_s"
var top1ScoreField = "top_1_score_d"
doc.addField(top1ClassField, modelOutput.get("top_1_class")[0])
doc.addField(top1ScoreField, modelOutput.get("top_1_score")[0])Best practices for configuring the Classification job
This job analyzes how your existing documents are categorized and produces a classification model that can be used to predict the categories of new documents at index time.
For detailed configuration instructions and examples, see Classify New Documents at Index Time or Classify New Queries.
This job takes raw text and an associated single class as input. Although it trains on single classes, there is an option to predict the top several classes with their scores.
At a minimum, you must configure these:
-
An ID for this job
-
A Method; Logistic Regression is the default
-
A Model Deployment Name
-
The Training Collection
-
The Training collection content field, the document field containing the raw text
-
The Training collection class field containing the classes, labels, or other category data for the text