Fusion 5.3.0
Release date: November 18, 2020
Component versions:
| Component | Version |
|---|---|
Solr |
8.6.3 |
ZooKeeper |
3.5.7 |
Spark |
2.4.5 |
Kubernetes |
GKE, AKS, EKS 1.19 Rancher (RKE) and OpenShift 4 compatible with Kubernetes 1.19 OpenStack and customized Kubernetes installs not supported. See Kubernetes support for end of support dates. |
Ingress Controllers |
Nginx, Ambassador (Envoy), GKE Ingress Controller Istio not supported. |
More information about support dates can be found at Lucidworks Fusion Product Lifecycle.
Solr is updated from version 8.4.1 to 8.6.3.
|
Looking to upgrade?
Check out the Fusion 5 Upgrades topic for details. |
New Features
Fusion
Data Models
Data models simplify the process of getting started with Fusion by providing pre-configured objects to reduce the effort spent on basic starting tasks. This helps keep documents consistent between datasources and intuitive to the object’s type.
Access data models in the Fusion UI by navigating to Indexing > Data Models.
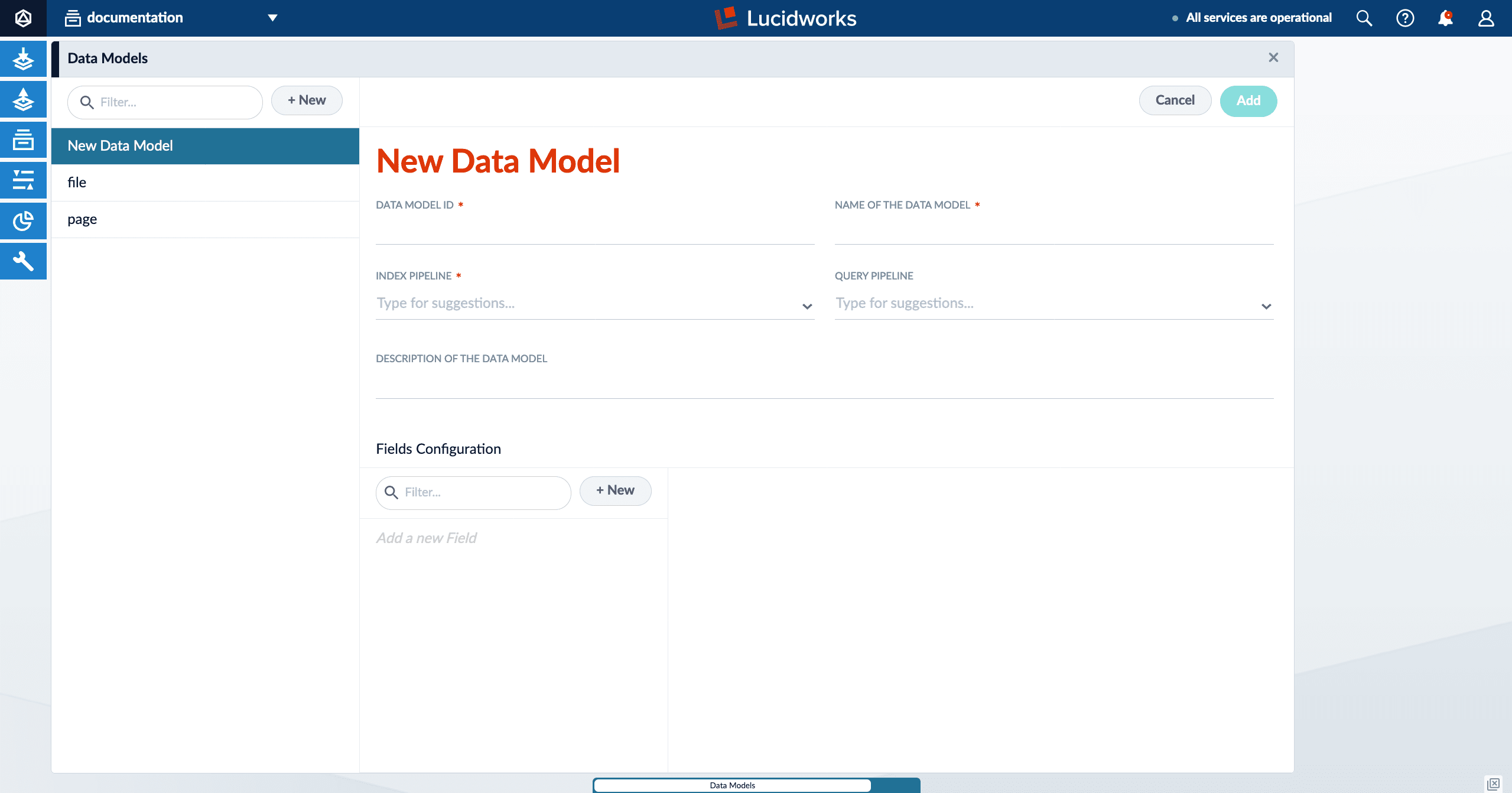
Some connectors include built-in data models as a standard component. Others require you to manually create data models.
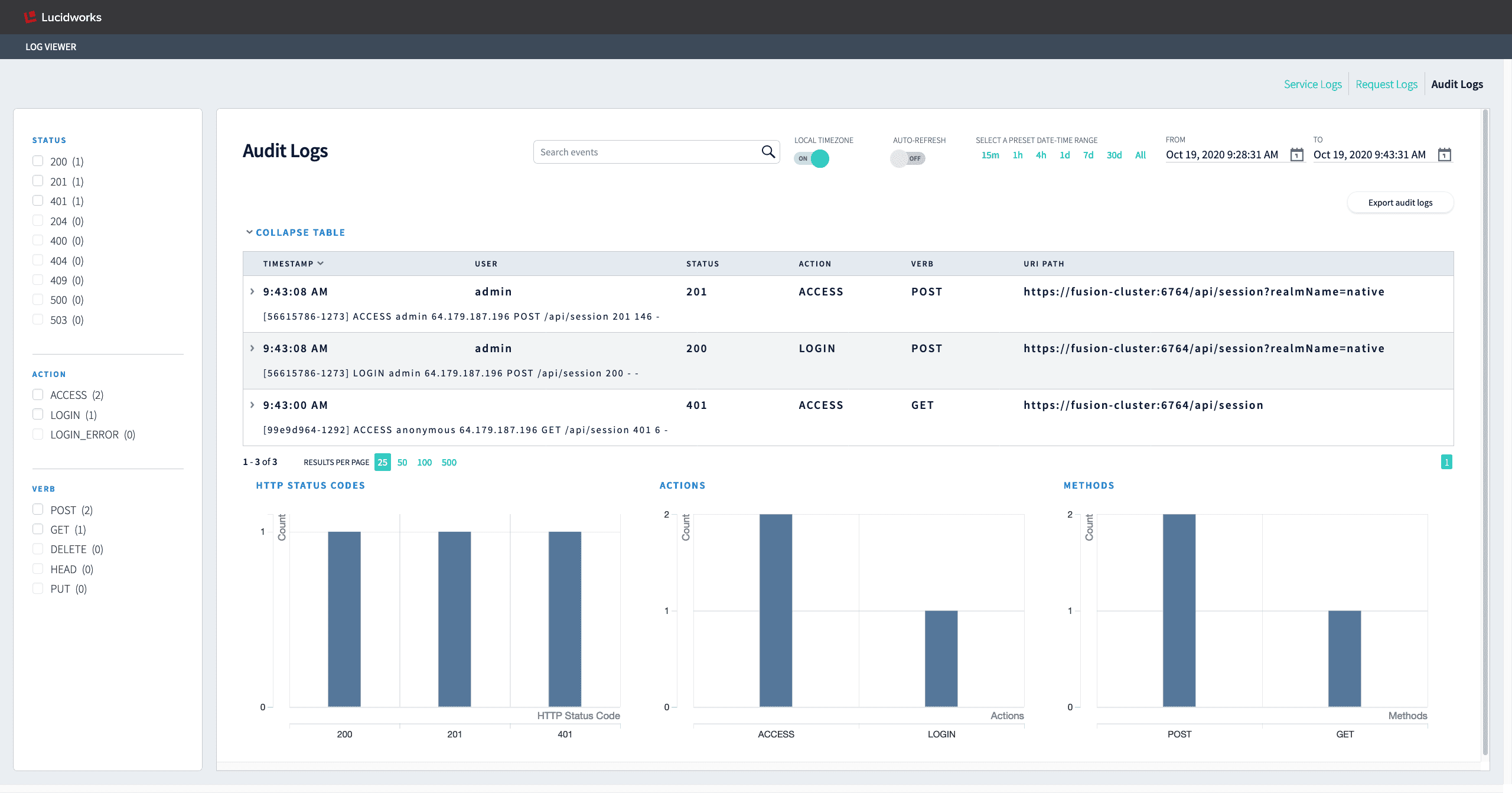
Audit Logs
Audit Logs are added to the DevOps Center’s Log Viewer. Audit logs provide you with a resource for tracking actions within Fusion, including the date, time, user responsible, and more.
Subscriptions
Subscriptions in Fusion allow you to create and configure subscriptions using Apache Pulsar.
In Fusion 5.3.0, Subscriptions are included in the Fusion UI under Indexing > Subscriptions.
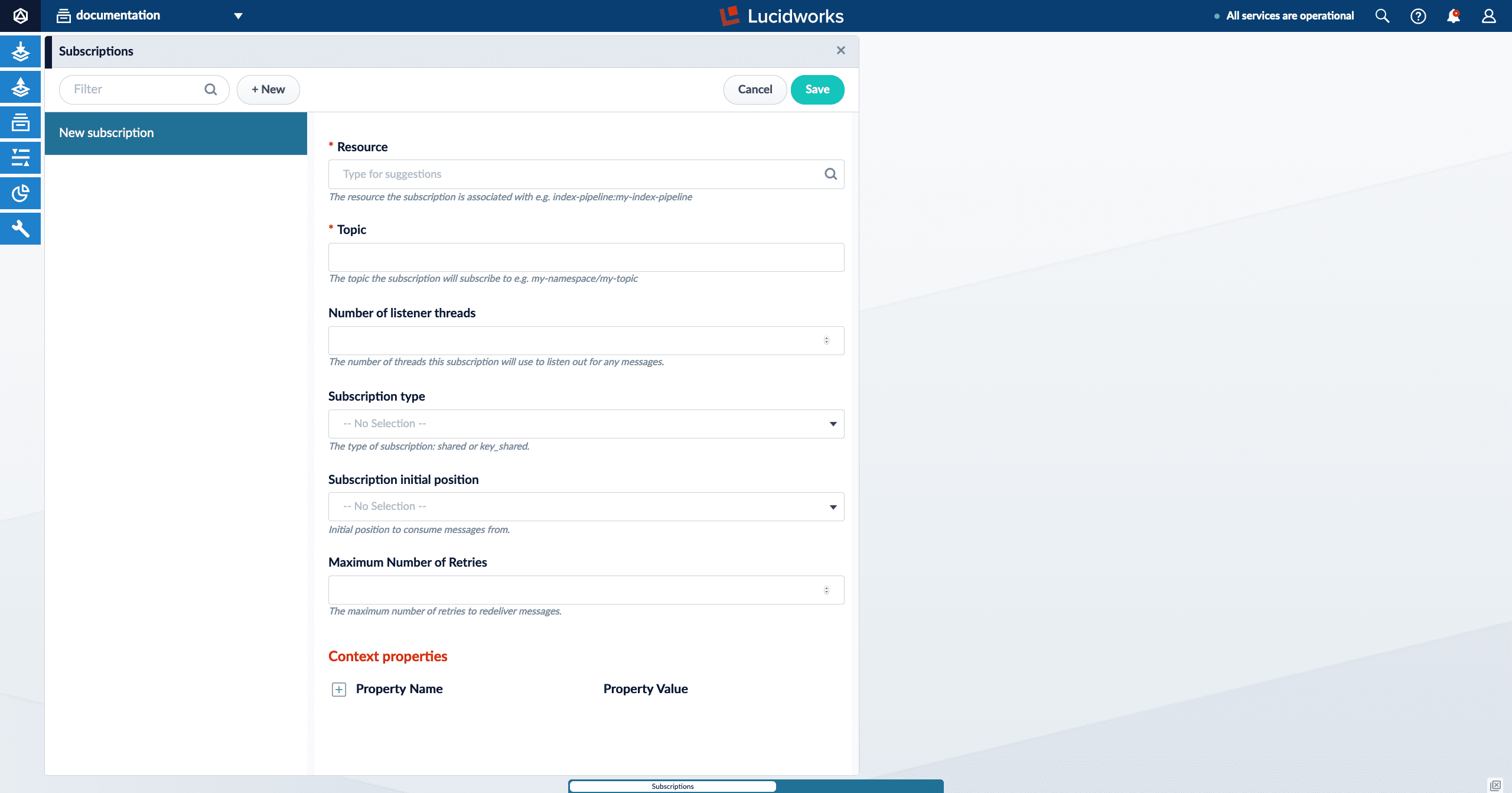
See Subscriptions UI for more information.
Fusion
New features for Smart Answers
Milvus integration
Fusion 5.3 extends support for semantic search using vectors and embeddings by integrating with Milvus, a highly scalable embeddings engine that allows Fusion to streamline the methodologies that use deep learning for question/answer solutions like Smart Answers, recommendations based on similarity, and regular search. Milvus MySQL is included for metadata management.
A number of new components are introduced to manage and utilize Milvus:
- New jobs
- New pipelines
-
-
For the latest configuration instructions, see Configure The Smart Answers Pipelines.
- New index pipeline stage
- New query pipeline stages
New deep learning models
In Fusion 5.3, we are refreshing our deep learning models methodologies to be used in training and inference for semantic search-based Smart Answers. The following models are new in this release:
|
The |
|
These are distilled, performance-optimized versions of BERT models designed to be used on scale. Available for English language and multilingual applications. |
|
This is a BERT model that was pre-trained on large-scale biomedical corpora which makes it more suitable for biomedical domain applications. |
For configuration details, see Train A Smart Answers Supervised Model, Train A Smart Answers Cold Start Model, and Advanced Model Training Configuration for Smart Answers.
Answer Extraction
To enhance how our Smart Answers customers interact with results sets that are composed of large documents, Fusion 5.3 adds Answer Extraction, allowing you to extract a paragraph, sentence, or phrase to answer questions.
When a large document is presented as a result to a query, Answer Extraction extracts the sentences out of the document that are most similar to the query content. To configure this feature, you train a model that gets deployed at the end of the Smart Answers query pipeline stage, after the resulting set of large documents is returned from Solr for final ranking. The model outputs the sentences from each document that are the most similar to the query.
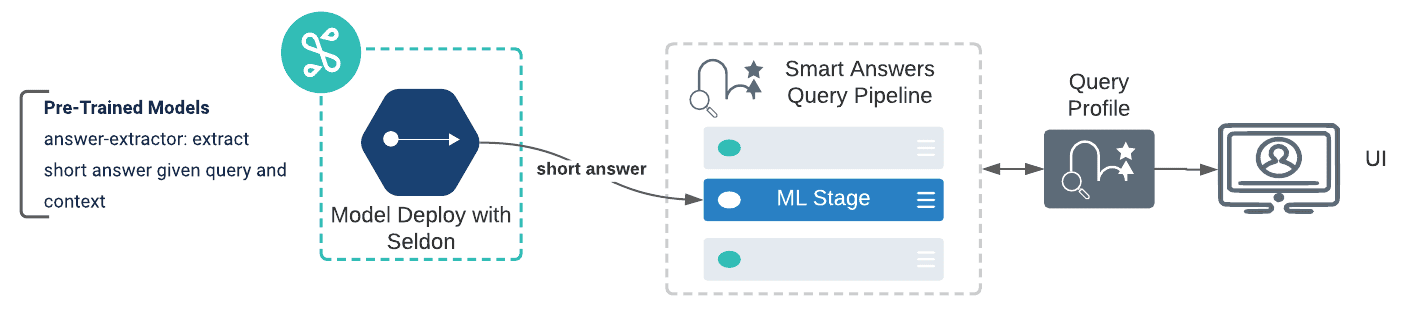
The Answer Extraction model is now available from the Lucidworks official Docker to be deployed as a Seldon model. See Extract Short Answers from Longer Documents for detailed configuration steps.
New Seldon model: spaCy
The spaCy NER and POS model that formerly shipped with Fusion is now available only from the Lucidworks official Docker to be deployed as a Seldon model.
The new Seldon model is compatible with Fusion 5.1+ and existing NLP Annotator stages.
Trending Recommender job
The new Trending Recommender job analyzes signals to measure customer engagement over time. Use this job to identify spikes in popularity for specific documents or products, then display those items to your users or analyze the trends for business purposes. You can configure any time window, such as daily, weekly, or monthly.
For detailed steps to configure this job, see Identify Trending Documents or Products.
Build Training Data job
The new Build Training Data job constructs the training data required for query-time classification, that is, predicting the categories most likely to satisfy a query.

For detailed configuration steps, see Classify New Queries.
Connectors
Connectors SDK 3.0
Version 3.0 of the Java Connector Development is now available. See the Javadocs for complete details.
| Custom connectors created with previous versions of the SDK must be recompiled with version 3.0 for compatibility with Fusion 5.3. |
Remote connector support
Remote connector support returns in Fusion 5.3.0. See Use a Remote Connector with Pulsar Proxy for more information.
Windows Share SMB 2/3 (V2)
The Windows Share connector can access content in a Windows Share or Server Message Block (SMB 2 and 3 protocols)/Common Internet File System (CIFS) filesystem.
For more information, see the Windows Share SMB 2/3 V2 connector reference documentation.
Google Drive (V2)
Unresolved directive in <stdin> - include::/fusion-connectors/reference/googledrivev2.asciidoc[tag=intro]
For more information, see the Google Drive reference documentation.
JDBC (V2)
Connect to any JDBC database.
For more information, see the JDBC V2 connector reference documentation.
AWS S3 (V2)
The AWS S3 V2 connector crawls items in a single bucket. You must specify the bucket name and AWS region in which that bucket is located.
You may crawl specific items in a bucket. If no items are specified, the entire bucket will be crawled.
For more information, see the AWS S3 V2 connector reference documentation.
Predictive Merchandiser
JSON Blob rule type
A new rule type, JSON Blob, is added. This rule type allows you to pass arbitrary JSON blobs to your frontend when a rule fires:
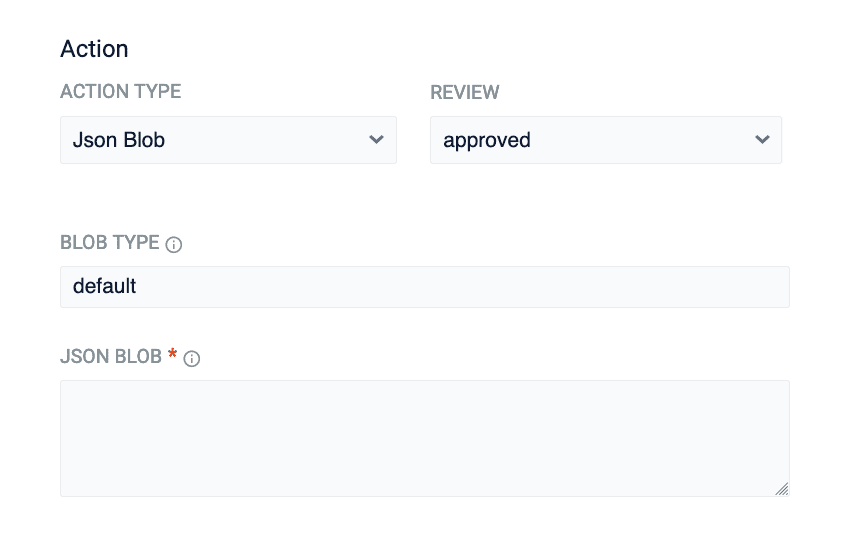
Detail Page template
A new template, Detail Page, is added. This template allows you to configure what details and zones are displayed when a user views a product’s details. To configure this template, navigate to Templates and edit Detail Page. You can also configure this template visually in the Merchandiser screen by hovering over a product, clicking the Detail Page button, clicking the Start Task button, and clicking the Edit Template button.
Improvements
Fusion
-
Argo-based jobs can now be configured to access cloud storage. See Configure An Argo-Based Job to Access GCS and Configure An Argo-Based Job to Access S3.
-
A new option is added to enable ephemeral users on the following realms: OpenID Connect, SSO Trusted HTTP, JWT, LDAP, and SAML. This improves performance for Fusion deployments with a large number of user accounts. To enable, set
ephemeralUserstotrue.Ephemeral users are not created in Zookeeper, so the autoCreateUserssetting has no meaning ifephemeralUsersare enabled. The information needed to create a user must be taken from realm configuration and from IdP.
-
V2 connector configurations are now persisted with default values.
-
Improved error messages for Fusion SQL.
-
Index and query stage schema is now returned alphabetically from
/api/index-stages/schema.
-
String templates are now supported in REST stages and collection parameters for the rules and text tagger stages.
Fusion UI
In addition to minor improvements, several notable improvements are made to the Fusion UI.
Fusion DSL integration
Fusion Domain Specific Language (DSL) provides expected search results as a JSON response in a way that reduces search query complexity for the user.
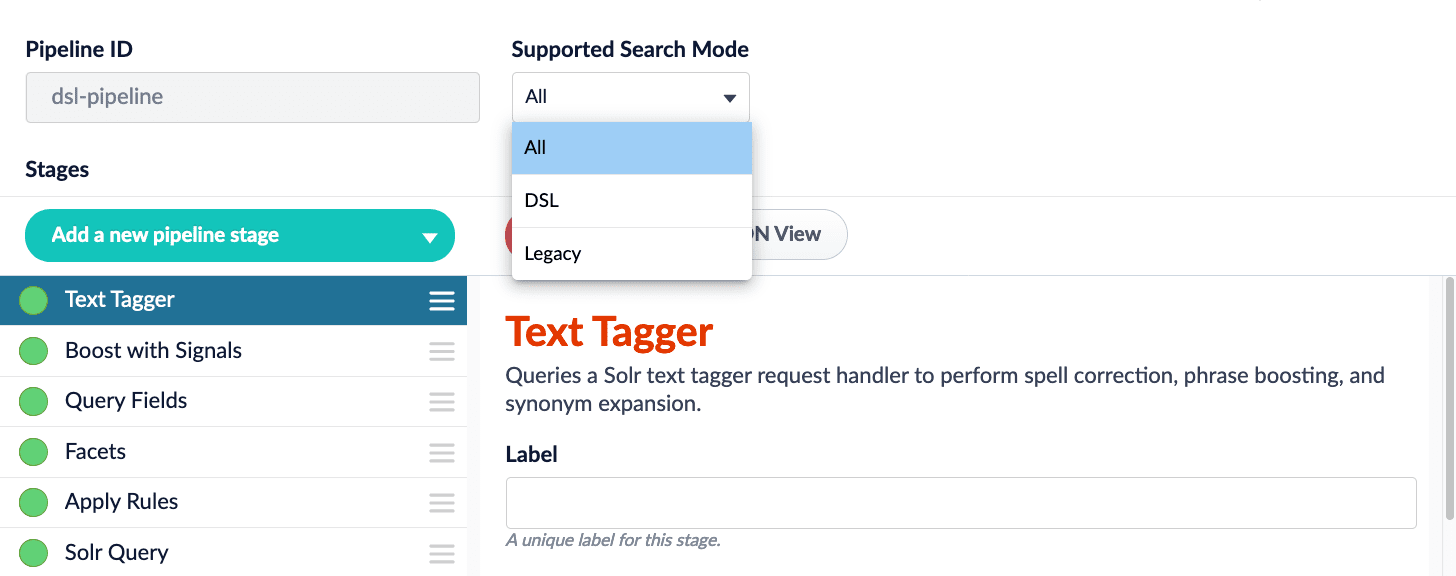
In Fusion 5.3.0, DSL is integrated with the UI:
-
Query Pipelines. Select which search modes to use with your query pipeline: DSL, Legacy (Solr), or All (both). Your selection is reflected in the Query Workbench.
-
Query Workbench. While entering queries in the Query Workbench, click the active search mode to toggle between DSL and Solr.
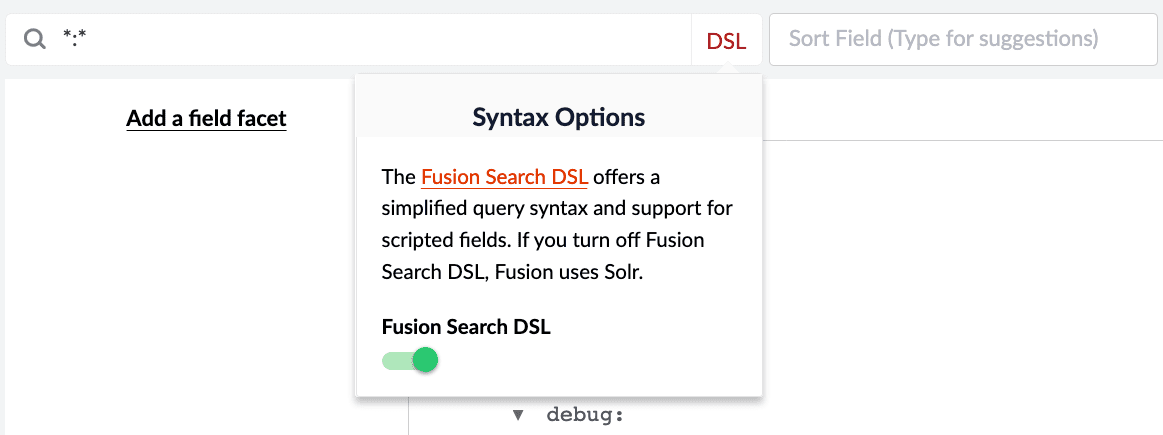
This option is only available if your pipeline supports All search modes. Change your View As setting to JSON to how the response results change.
-
Query Pipeline Stages. Not all query pipeline stages support DSL. If you add an incompatible stage while in DSL mode, the stage will be flagged accordingly:
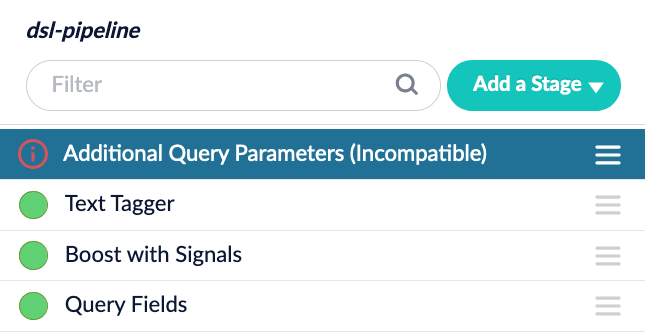
However, a new stage is added to extend DSL support to incompatible stages. Click Add a Stage and select the DSL to Legacy Parameters stage. When loaded before the incompatible stage(s), this stage converts the DSL request to legacy parameters so it can still be processed by the incompatible stage.
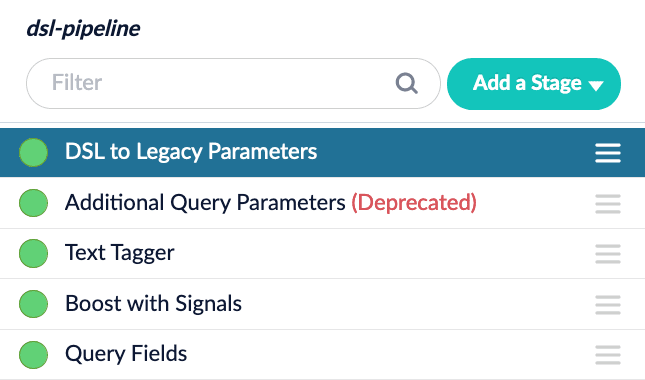
See the DSL documentation for more details on what you can do.
Minimap
A minimap is added to the bottom of the Fusion UI, allowing you to quickly move between open panels:
-
Click one of the items to move your focus to the corresponding panel
-
Close panels by hovering over an item and clicking the X that appears
-
Close all panels by clicking the Close all button:

Panels with unsaved changes will not be closed.
Toggle Sampling in the Index Workbench
The Index Workbench now features a Sampling toggle at the bottom of the results.
-
When set to On, the results update with every change you make:

-
When set to Off, the results no longer update, but a Refresh button appears to manually update the results:

Pin result fields
You can now pin result fields in the Index Workbench by hovering over a field and clicking the Pin icon that appears.

Pinned results are moved to the top of the document fields list, allowing you to quickly find the fields most relevant to the tweaks you are working on.
Fusion
-
You can now view, edit, publish, and delete unpublished rules created by other users in the Rules Editor.
-
AI jobs can now read and write from GCS directly. Meaning, the customer engagement data aka signals do not necessarily have to be stored in Solr for the jobs to work. This development is primarily to avoid situations where Solr is unable to keep up with the write requests from the jobs. GCS handles high speed, high scale writes efficiently.
Fusion SQL
Enhancements in the Fusion SQL integration for notebooks and visualization platforms:
-
Jupyter. Learn about connectivity set-up and usage examples of Fusion SQL with Jupyter notebooks in Use Jupyter with Fusion SQL.
-
Apache Superset. Available documentation for connectivity set-up and usage of Fusion SQL with SuperSet BI platform in Use Superset with Fusion SQL
Predictive Merchandiser
-
Predictive Merchandiser templates now support staging and publishing actions similar to rules. This allows you to draft templates and zones without affecting the production experience.
-
Predictive Merchandiser zones adds a new configuration option, UI Treatment. This field allows for arbitrary text in the response when rendering this zone. This text is used by your frontend, when configured to do so, to determine how the zone is displayed. By utitilizing this field, you can use the same zone more than once on the same page but display the results differently.
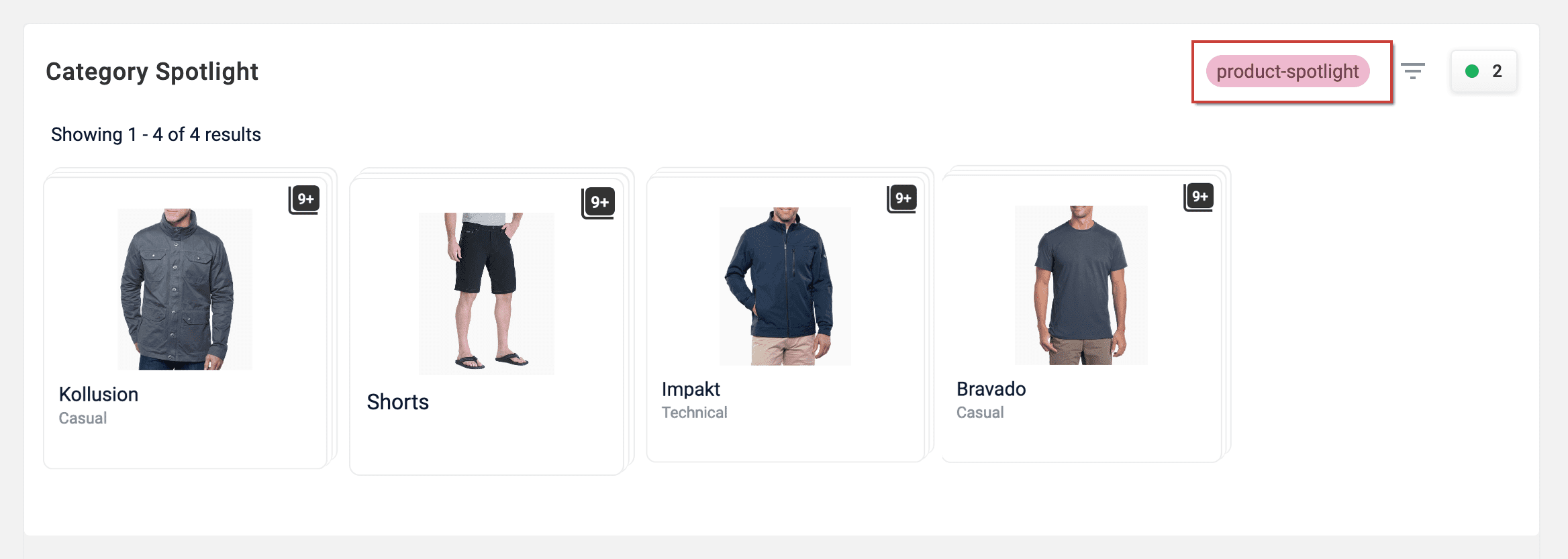
-
Predictive Merchandiser zones adds a new configuration option, Omit Filters From Query. When set to
true, this zone ignores allfqfilter parameters. For example, if you have a category landing page that is filtering results by category, this configuration option allows you to display items outside of that category.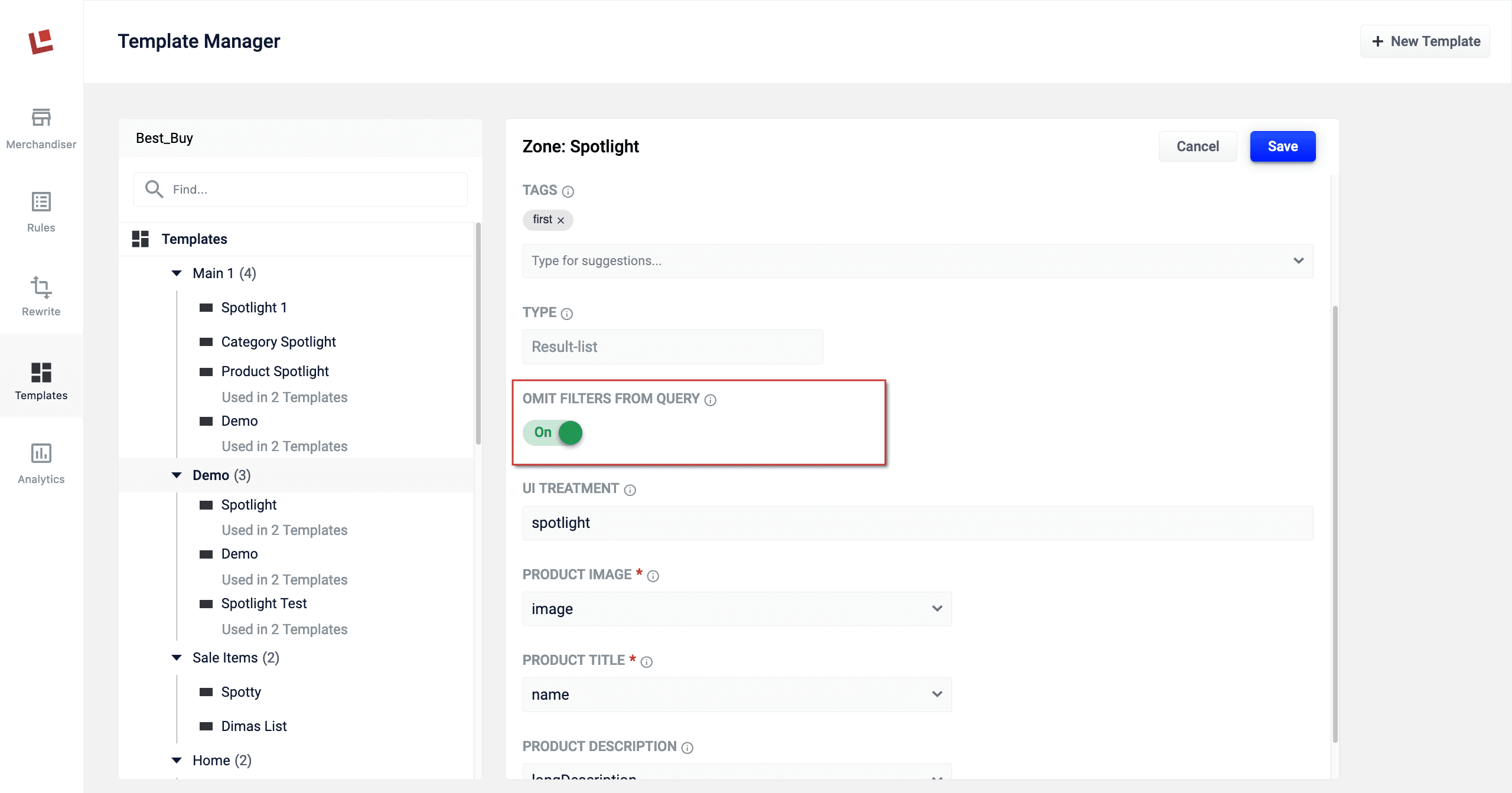
-
When attempting to navigate away from an unsaved template, a confirmation modal is now displayed to help prevent the loss of progress.
-
Miscellaneous UI improvements.
Bug fixes
Fusion
-
You can now easily select text in the log view without inadvertently collapsing the row.
-
You can no longer save invalid field mapping configurations. Errors are now reported for invalid configurations.
-
Fixed a bug that prevented jobs from saving multiple times.
-
Fixed incorrect error messages in the Blob Store.
-
Fixed a bug that sometimes prevented Query-to-Query Session-based Similarity jobs from saving.
-
Reduced the number of requests sent to the Kubernetes API service to reduce the chance of exceeding the Kubernetes call limit.
-
Fixed an issue with the Query Workbench that sometimes caused a Java heap space error when a query returned a large number of documents (over 1 million).
Fusion
-
Fixed a bug in the Rules Editor that prevented the pagination from working as expected.
Connectors
-
Fixed a bug that sometimes prevented V2 connectors that use multiple phases to fetch documents in later phases.
Predictive Merchandiser
-
A bug is fixed that resulted in different filter behaviors between the API and the UI. Filters now apply to all zones.
-
Fixed a bug that occasionally caused all rules to show as pinned rules if a multiple zones shared a pinned rule.
-
Fixed a bug that prevented rules with disallowed symbols from showing when the Show Applied Rules button was clicked in the Details view. Symbols are now encoded.
-
Fixed a bug that prevented product groups from opening when facets were selected.
-
Fixed an issue with Predictive Merchandiser templates that resulted in zones and templates remaining available after the associated app was deleted and recreated.
Other changes
-
The Evaluate QnA Pipeline job is now called Smart Answers Evaluate Pipeline.
-
The sql-jdbc service, which serves the stateful JDBC connections, is now restricted to a single pod.
Notable documentation updates
Connectors download and installation
The connectors documentation is updated to address user feedback and clarify how connectors are downloaded and installed in each version of Fusion. The changes include:
-
New how-to pages:
-
A link is added to the Connectors index page that includes to the correct steps to install a connector, depending one the version of documentation you are viewing the Connectors index page.
-
Corrections are made so the connector documentation accurately includes related topics, depending on the version of documentation you are viewing.
Business Rules
The Business Rules documentation is totally revamped for all versions of the Fusion docs. The changes include:
-
New concepts pages:
-
New reference pages:
-
A new how-to page:
-
A rewritten how-to page with clearer and more accurate instructions:
API reference docs
The REST API reference docs are updated to be more accurate and make topics easier to discover. Changes include:
-
A reorganized index page that makes API topics easier to find.
-
The sidenav is reorganized to reflect the changes.
-
Descriptions are added and updated for each API.
To get started reading the improved API documentation, see REST API Reference.
Deprecations
-
Sharepoint Online V1 connector
This connector has been deprecated as of 5.3.0. Alternatively, Lucidworks recommends using the V2 connector.
-
The JDBC V1 connector is deprecated in 5.3 and will be removed in 5.4. In Fusion releases 5.4 and later, use the JDBC V2 connector.
-
The config-sync Fusion microservice was deprecated and removed. It is no longer available in any release of Fusion, including Fusion 5.3.
Removals
-
The AWS S3 V1 connector is not available after Fusion 5.3.
-
The System > Solr Clusters panel is removed from the Fusion UI.
Known issues
Fusion
-
Database credentials can be visible in the Indexing Service Logs. This issue is fixed in Fusion 5.4.
-
Some log messages are dropped when encoding them as JSON in the Logging index pipeline stage. This issue is fixed in Fusion 5.4.
-
In the Jobs configuration menu, the weight field isn’t passed into the pull data, causing an error. This issue is fixed in Fusion 5.4.
-
Field mappings are not retained in web datasources. This issue is fixed in Fusion 5.3.3 and 5.4.
-
Datasources API call responses contain stack traces. This issue is fixed in Fusion 5.3.3 and 5.4.
-
Evaluation jobs fail to push data to Solr when non-strings are used in the Return Fields field. This issue is fixed in Fusion 5.3.1.
-
In the Query Workbench, highlighted results items are displayed in Solr syntax instead of Domain Specific Language (DSL) syntax. This issue is fixed in Fusion 5.4.
-
Additional fields in search results disappear when many items are pinned in the Indexing Workbench. This issue is fixed in Fusion 5.4.
Predictive Merchandiser
-
Basic security roles that are set up in Fusion do not work as expected with Predictive Merchandiser’s Templating API permission. This issue is Fixed in Fusion 5.4.
-
Creating a template that does not contain a main results list makes the close button unusable. This issue is fixed in Fusion 5.4.
-
Using the dialog to insert a pin causes the page to refresh and switch templates. This issue is fixed in Fusion 5.4.
-
Pinned results do not stay in the intended position. This issue is fixed in Fusion 5.4.
Connectors
-
The delete by ID feature in the Access Control Collection (ACL) can potentially delete the wrong documents if the ID includes whitespace or special characters. This issue is fixed in Fusion 5.4.
-
When adding gRPC authentication headers, the Machine Learning Index Stage fails to retrieve the ServiceAccount JWT value while checking
SecurityContextHolder.getContext().getAuthentication()if ServiceAccount is set in thread context. This results in authentication errors when processing messages coming from Pulsar Subscriptions.
-
The Sitecore connector fetches the wrong
ItemPath. This issue is fixed in Fusion 5.4.
-
The Active Directory (AD) V2 connector displays an
Error when processing page LdapUserPagemessage while crawling. This issue is fixed in Fusion 5.4.
-
The Windows Share SMB 2/3 V2 connector displays a
STATUS_NOT_SUPPORTEDerror. This issue is fixed in Fusion 5.4.
-
Validation requests in the Sitecore connector plugin time out due to a
classpathissue. This issue is fixed in Fusion 5.4.
-
The gRPC service (
connectors-rpc) does not start when a Fusion deployment is behind a proxy. This issue is fixed in Fusion 5.4.
-
The V2 connector runtime quickly runs out of memory. This issue is fixed in Fusion 5.4.
-
The JIRA Connector displays an error when signatures are null. This issue is fixed in Fusion 5.4.