Fusion 5.4.0
Release date: April 23, 2021
Component versions:
| Component | Version |
|---|---|
Solr |
8.8.2 |
ZooKeeper |
3.6.2 |
Spark |
2.4.5 |
Kubernetes |
GKE, AKS, EKS 1.18 Rancher (RKE) and OpenShift 4 compatible with Kubernetes 1.18 OpenStack and customized Kubernetes installs not supported. See Kubernetes support for end of support dates. |
Ingress Controllers |
Nginx, Ambassador (Envoy), GKE Ingress Controller Istio not supported. |
More information about support dates can be found at Lucidworks Fusion Product Lifecycle.
Solr is updated from version 8.6.3 to 8.8.2.
|
Looking to upgrade?
Check out the Fusion 5 Upgrades topic for details. |
New Features
Fusion
In addition to Fusion’s built-in query stages, Lucidworks now provides a Query Stage SDK for developing your own custom query stages with Java. Resources are provided in a public GitHub repository.
A new Helm property, solrRequestLogEnable, enables the request log features of Solr when you set it to "true"; the default is "false".
Grouping attributes can now be configured as part of the Query Fields stage. Previously, grouping attributes could only be configured in the Additional Query Parameters stage.
JavaScript blobs can now be edited directly inside the Fusion UI using one of these interfaces:
-
In the blob manager by clicking Edit Blob.
-
In the Managed Javascript index stage or Managed Javascript query stage, by clicking Edit in the Script Reference field.
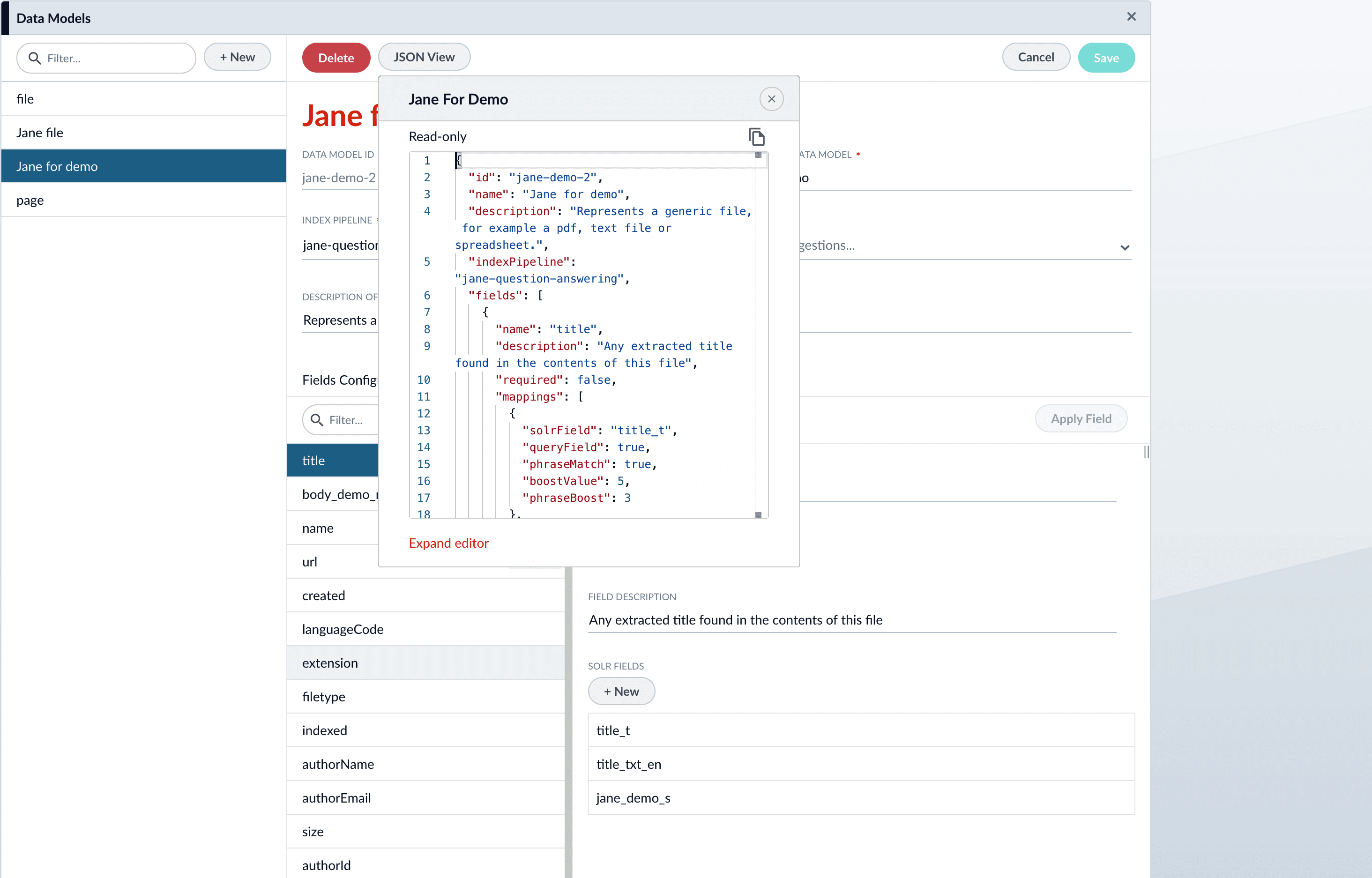
When adding a new data model, you can now paste it into the JSON view. Existing data models are read-only in the JSON view but their contents can be copied.
Apache Superset is now included as an optionally-deployable component of Fusion. See Enable Superset (Fusion 5.4 and up) for deployment instructions and Use Superset with Fusion SQL for a detailed tutorial.
Apache Tika is now a Fusion microservice instead of an in-pod child process, for improved reliability and memory usage.
A new stage for the Index Pipeline, Text Processing, applies simple text transformations to text fields in a document.
The new Transfer Collection to Cloud job copies your Solr collections to cloud storage.
The Detect Language index stage has new features enabled by these configuration keys:
-
languagesimproves accuracy by specifying a limited set of candidate languages. Select the languages found in your content to prevent matching any other languages. -
minimumConfidencesets the minimum confidence score, to filter out low-confidence language matches. -
When
returnAllMatchedWithConfidenceScoresis enabled, the stage returns all languages whose confidence scores exceed the minimum, along with their corresponding confidence scores. Otherwise, only the language with the highest confidence score is returned.
Fusion AI
A new rewrite type, Remove Words, is added to the Rules Editor’s Rewrite screen.
Use a Remove Words query rewrite to remove particular phrases from queries. Unlike other rewrites, Remove Words rules are entered manually and aren’t generated by a job.
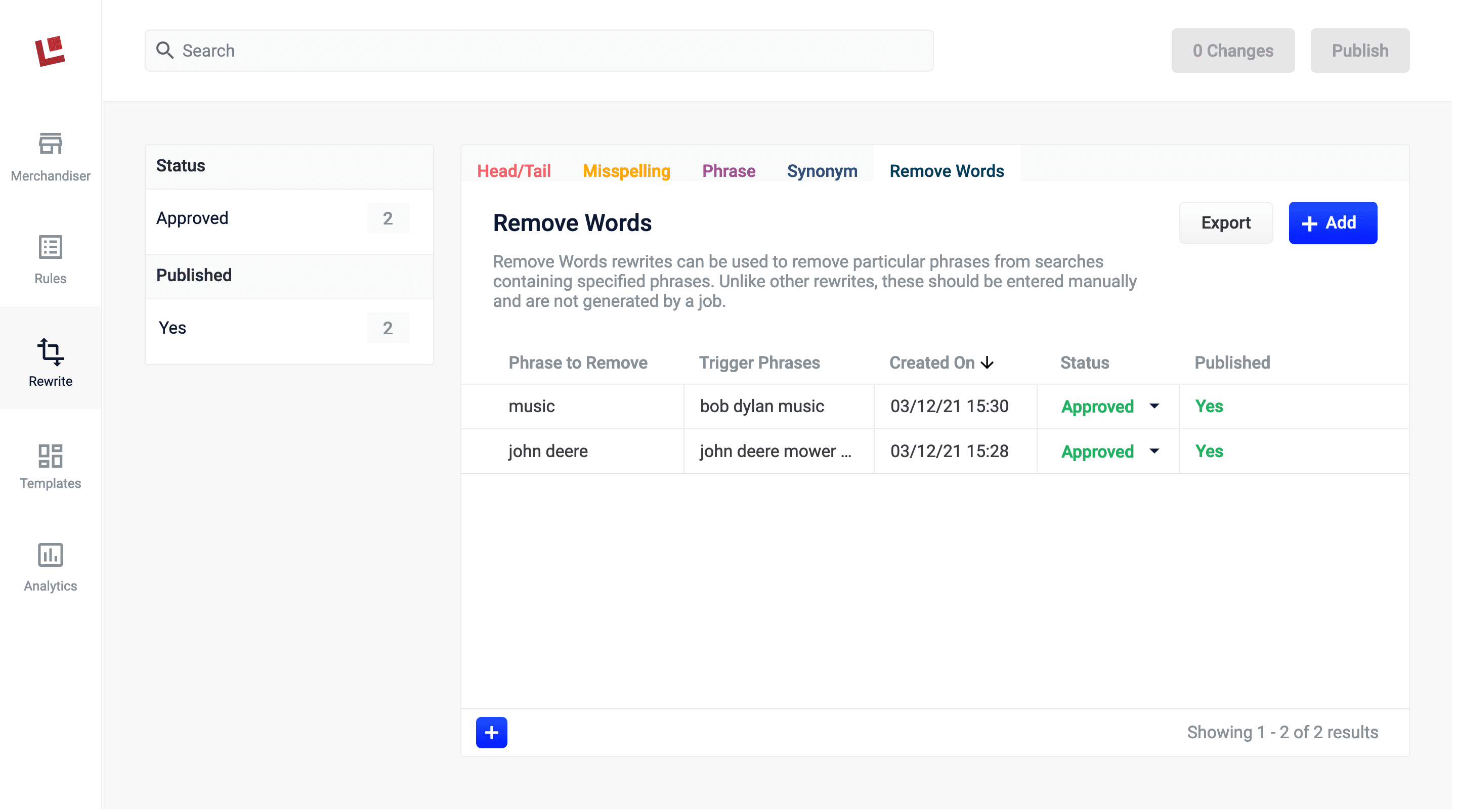
To learn how to use Remove Words and other query rewrites in the Rules Editor, see Use Query Rewrites in the Rules Editor.
The new Data Augmentation job provides various tasks designed to augment training and/or testing data, such as Backtranslation, Split Word, and Synonym Substitution.
Store the training blobs from your trained models in cloud storage with the new Upload Model Parameters to Cloud job.
Connectors
The ServiceNow connector has a new fields_to_crawl property that defines the fields to be indexed per table; this also improves crawl performance.
-
A new caching interface is available in the
com.lucidworks.fusion.connector.plugin.api.cachepackage. -
SDK-based connectors can now emit a date type using
LocalDateTimein theMapBuilderclass. -
SkipandErroritems now accept metadata. Fields have been removed removed fromSkipitems; note that this will break existing connectors that use fields inSkipitems. -
New packages:
com.lucidworks.fusion.connector.plugin.api.cache,com.lucidworks.fusion.connector.plugin.api.exceptions,com.lucidworks.fusion.connector.plugin.api.resource. -
New classes:
BlobResource,BlobResourceClient,CacheManager,ConnectorPlugin.FetcherDef.BuilderContent.ContentEmitter,ContentEmitException,FetchGroup,StaticSecuritySpec.UserPrincipalCase. -
Some classes have been removed:
ContentFetcher.PostFetchContext,ContentFetcher.PreFetchContext,FetcherContext.AbstractPostFetchContext,FetcherContext.AbstractPreFetchContext,FetcherContext.DefaultPostFetchContext,FetcherContext.DefaultPreFetchContext,FetcherContext.PostFetchContext,FetcherContext.PreFetchContext,PostFetchResult,PreFetchResult.
Use start() and stop() in the Fetcher to replace the preFetch() and postFetch() methods that were previously deprecated and are now removed.
|
See the Connectors SDK 4.0 Javadocs for details.
In the Fusion UI, V1 and V2 connectors are now differentiated in the connectors list.
Predictive Merchandiser
You can now configure the data displayed in the Analytics screen to highlight the signals most relevant to your needs.
To learn how, see Use the Analytics screen in the Rules Editor.
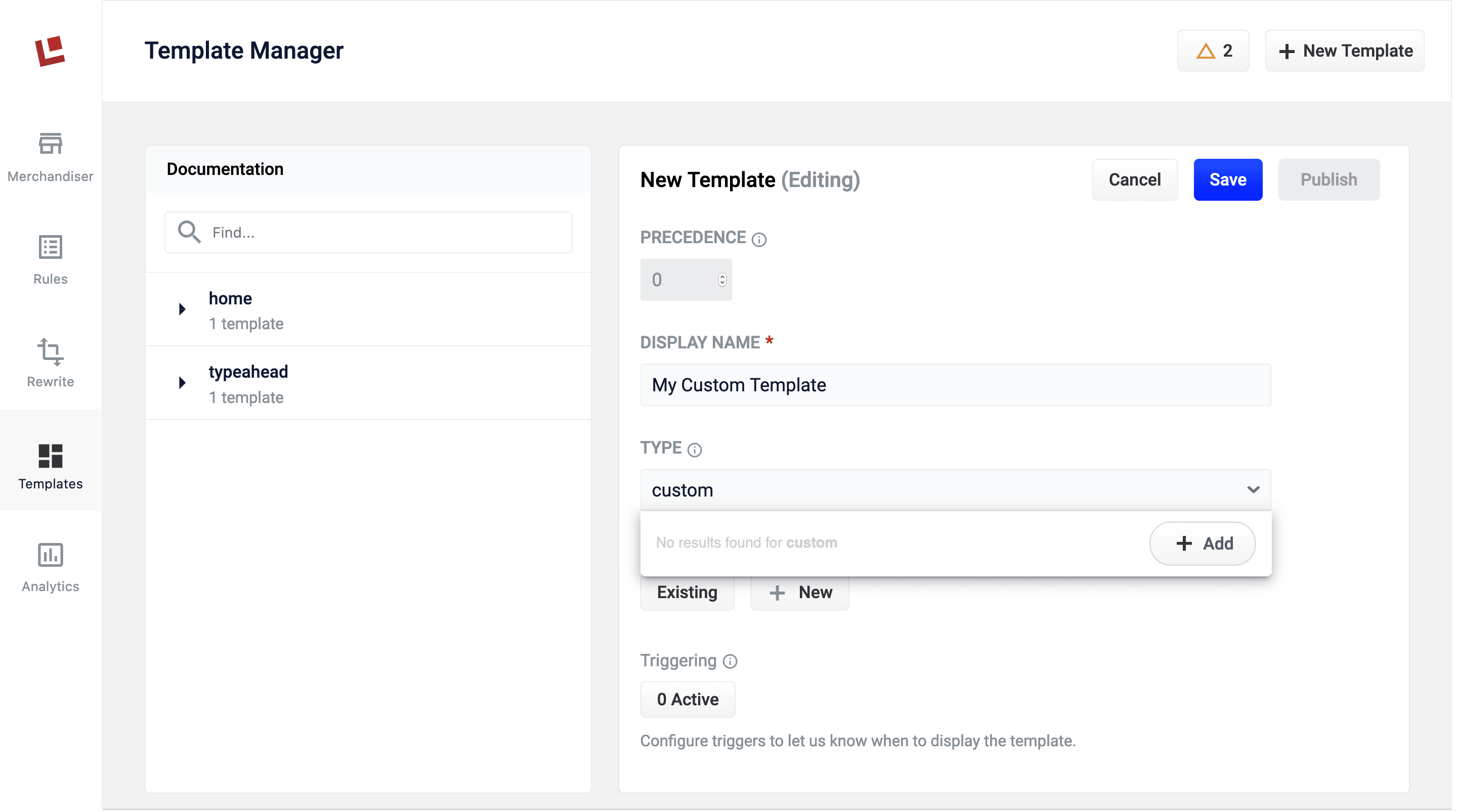
The Rule Editor’s Templates screen now allows you to create custom template types. This allows you to add more options for curating page types in your search application.
Improvements
Fusion
-
The Apache Pulsar subscription type cannot be changed, but a subscription can be deleted and recreated with the desired type. This eliminates conflicts caused by a type change.
-
Template ID and zone metadata were added to the Templating API’s
renderendpoint. Newrenderendpoints were also added to render templates by their specific template IDs.
-
You can now configure the search mode (
all,legacy, orDSL) for any query profile or query pipeline.
-
Search DSL now supports grouping for facets.
-
Indexing service logs now include
COLLECTION_NAME_lw_batch_idto allow searching for errors associated with a specific connector job. Several additional stack tracing improvements were made.
Fusion AI
-
The BPR Recommender job can now filter out low-interaction users with a new
minNumUserUniqueClicksproperty.
-
The default field names for Trending Recommender jobs now match the default names of the aggregated signals fields instead of raw signals fields.
-
The default configuration values for the Detect Language index stage have been updated for better accuracy and fewer "unknown" language results.
-
The Machine Learning Model Service now deletes models asynchronously for increased performance.
-
The Milvus Ensemble query stage has a new
thresholdparameter that excludes items whoseensemble_scorevalue is lower than the threshold. This is useful in your Smart Answers pipeline configuration.
Connectors
-
The SharePoint V2 connector now indexes the metadata of files or attachments that do not meet the minimum or maximum size of file. Prior to the 5.4 release these files were ignored and not available for search.
-
Pulsar messages now record the
statsResponsefrom error messages.
Predictive Merchandiser
-
The Request Time is now an independent field separated from the proxy logs message field. See the log viewer in The DevOps Center for Request Time and additional log information. You can now search Request Time independently for further monitoring, troubleshooting, and incident investigation.
-
Domain-Specific Language (DSL) search is now compatible with Predictive Merchandiser.
-
Search rewrites created by Head/Tail Analysis job are now editable, similar to synonyms.
-
The limit on the number of boost/bury/suppress values in Facet Rules has been removed.
-
Predictive Merchandiser templates are now organized in a functional tree. The functional tree allows templates to be easily found in the Template Manager.
-
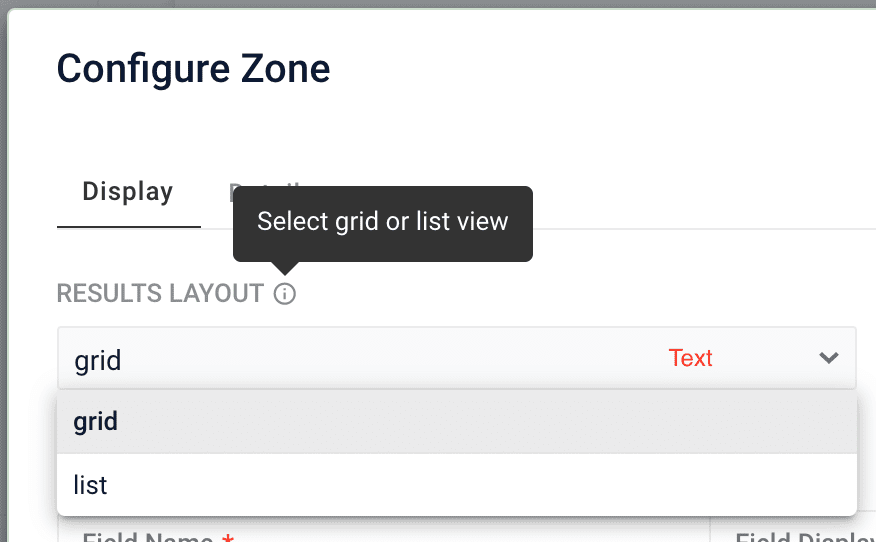
When creating and editing zones, you can now choose between grid and list layouts for results.
Bug fixes
-
The JDBC V2 connector on longer ignores the Max Documents value.
-
In the Resolve Multivalued Fields index stage UI, the
typeparameter was incorrectly labelled as "Field Name"; the label has been updated to "Type Name".
-
In Predictive Merchandiser, pinned products now stay in position instead of moving to the top of the results.
-
The JIRA Connector no longer throws an error when signatures are null.
-
A bug was fixed that caused garbled Japanese characters when editing a blob in the Fusion UI.
-
A bug was fixed that did not allow rules to trigger when filters include commas.
-
A bug was fixed that caused additional fields in search results to disappear when many items are pinned in the Indexing Workbench.
-
A bug that caused the V2 connector runtime to quickly run out of memory has been resolved.
-
A bug was fixed that prevented highlighted results items using Domain Specific Language (DSL) syntax in the Query Workbench.
-
A SharePoint connector security filtering bug, not allowing authorized files in a folder to be viewed, was resolved.
-
Resolved known issues with SnakeYAML and Tomcat CVEs.
-
A bug was fixed that prevented starting the gRPC service (
connectors-rpc) when a Fusion deployment is behind a proxy.
-
A bug was fixed that caused deleted values in the Partial Indexer stage to become empty strings.
-
A bug was fixed that caused Active Directory (AD) V2 connector exceptions.
-
A bug was fixed that caused the app import failure error "No such parsing configuration" with the SharePoint connector.
-
Fixed a bug that generated a
PluginCallerror when the SharePoint V2 connector starts.
-
A bug that could potentially delete documents when the document ID contains whitespace or special characters was resolved in the Access Control Collection (ACL) backend.
-
A bug was fixed that caused issues in the XML Transformation index pipeline stage.
-
The Indexing Service logs do not reveal database credentials.
-
Some SharePoint crawl timeout issues were resolved.
Known issues
Fusion
-
Validation errors occur when index pipelines are imported before data models. This issue is fixed in Fusion 5.4.2.
-
OpenID Connect realms do not work using proxy settings. This issue is fixed in Fusion 5.4.2.
-
After upgrading from 5.3.3 to 5.4.0, the About Fusion section displays the version incorrectly. This issue is fixed in Fusion 5.4.1.
-
SP Plugin pods fail with an
OOMKillederror.
-
In Fusion 5.4.0, the JAX-RS libraries were upgraded, causing Appkit’s webapps service to stop working as expected.
This issue is fixed in Fusion 5.4.2. Check out the Fusion 5 Upgrades topic for details on upgrading. Appkit apps deployed in Fusion 5.4.0 or 5.4.1 will not work, unless you downgrade the webapps microservice to 5.3.x. To do this:
-
Open the
customize_fusion_values.yamlfile. -
Update the webapps image tag value to
5.3.5, or any 5.3.x version number.webapps: image: tag: 5.3.5 livenessProbe: initialDelaySeconds: 60 javaToolOptions: "-Xmx1g -Dspring.zipkin.enabled=false -Dspring.sleuth.enabled=false -XX:+ExitOnOutOfMemoryError" ... -
Save your changes.
-
Run the upgrade script.
-
Removals
-
The Slack connector has been removed. This is due to Slack removing a critical API endpoint used in the connector,
channels.*. The Slack V2 connector is in development and will replace this connector.
-
The option to view metrics not supported in 5.x is now hidden in the Dashboards (Banana).
-
The
prefetch()andpostfetch()methods are removed from the Connectors SDK; now you use onlystart()andstop().
-
Index profiles no longer accept request parameters; these key/value pairs were never read or forwarded to the pipeline.
-
The class passed into the last parameter of a JavaScript stage has changed from
SolrClientFactorytoSolrClusterComponent. This change only impacts users with advanced JavaScript stages.