Configure the Smart Answers Pipelines (5.1 and 5.2 only)
Before beginning this procedure, train a machine learning model using either the FAQ method or the cold start method.
| For instructions for Fusion 5.3 and up, see Configure The Smart Answers Pipelines (5.3 and Up). |
Regardless of how you set up your model, the deployment procedure is the same:
The following default index and query pipelines for Smart Answers are automatically created when you create a Fusion app:
| Default index pipelines | Default query pipelines | ||
|---|---|---|---|
|
For encoding one field. |
|
Calculates vectors distances between an encoded query and one document vector field. Should be used together with |
|
For encoding two fields (question and answer pairs, for example). |
|
Calculates vectors distances between an encoded query and two document vector fields. After that, scores are ensembled. Should be used together with the |
See Configure the index pipeline below. |
See Configure the query pipeline below. |
||
1. Configure the index pipeline

-
Open the Index Workbench.
-
Load or create your datasource using the default question-answering index pipeline.
-
In the Machine Learning stage, change the value of Model ID to match the model deployment name you chose when you configured the model training job.
-
Change
documentFeatureFieldto the document field name to be processed and encoded into dense vectors. documentFeatureField variable in the “Model input transformation script” to the document field name to be processed and encoded into dense vectors. -
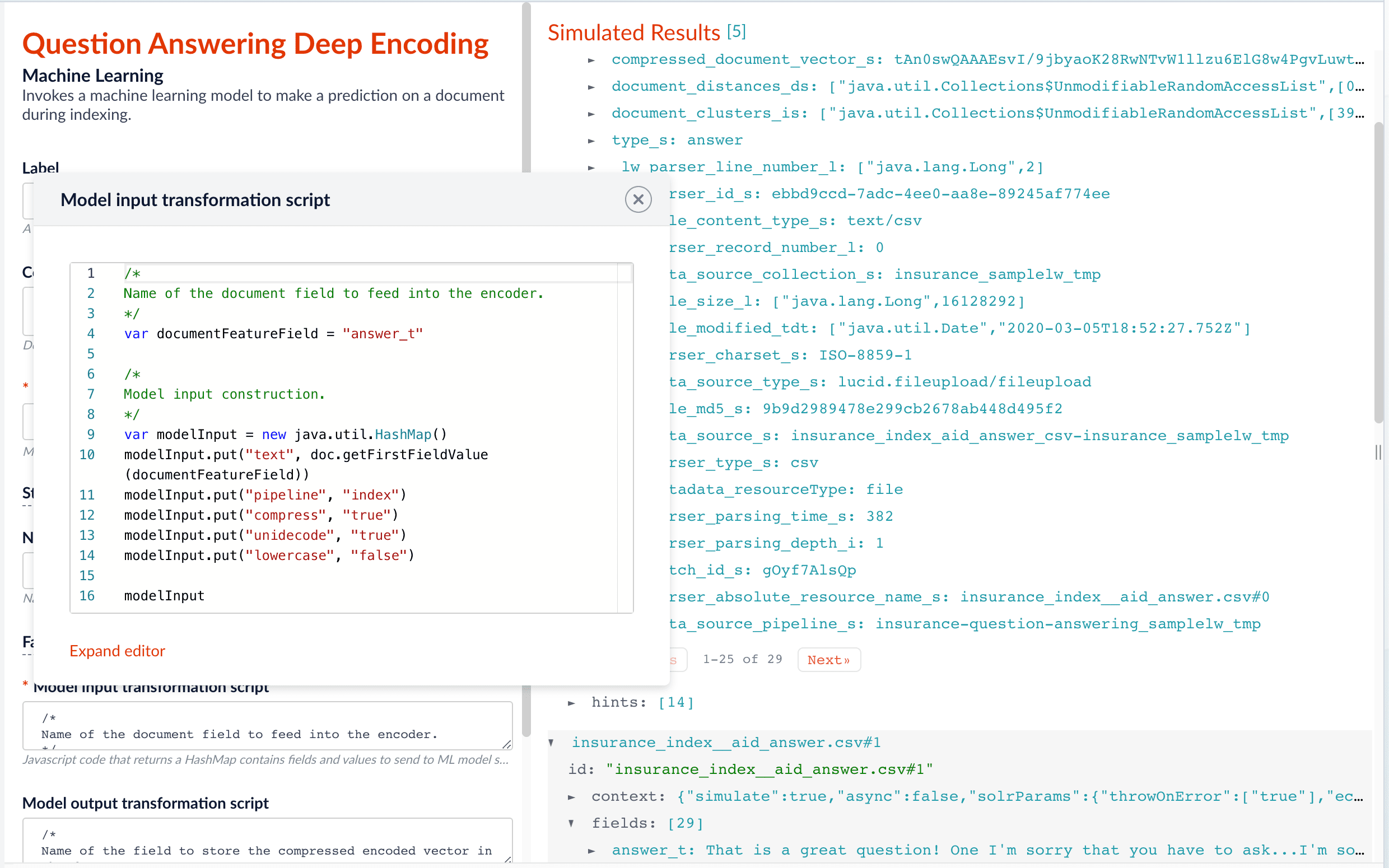
In the Model input transformation script field, enter the script below, replacing the
documentFeatureFieldvariable value (body_tby default) with the document field name to be processed and encoded into dense vectors./* Name of the document field to feed into the encoder. */ var documentFeatureField = "body_t" /* Model input construction. */ var modelInput = new java.util.HashMap() modelInput.put("text", doc.getFirstFieldValue(documentFeatureField)) modelInput.put("pipeline", "index") modelInput.put("compress", "true") modelInput.put("unidecode", "true") modelInput.put("lowercase", "false") modelInput -
Save the datasource.
-
Index your data.
2. Configure the query pipeline
-
Open the Query Workbench.
-
Load one of the default question-answering query pipelines.
-
In the Query Fields stage, update Return Fields to return additional fields that should be displayed with each answer, such as fields corresponding to title, text, or ID.
It is recommended that you remove the asterisk (
*) field and specify each individual field you want to return, as returning too many fields will affect runtime performance.Do not remove compressed_document_vector_s,document_clusters_ss, andscoreas these fields are necessary for later stages -
In the Machine Learning stage, change the Model ID value to match the model deployment name you chose when you configured the model training job.
-
Save the query pipeline.
Pipeline Setup Examples
Example 1: Index and retrieve the question and answer separately
Based on your search Web page design, you can put best-matched questions and answers in separate sections, or if you only want to retrieve answers and serve to chatbot app, please index them separately in different documents.
For example, in the picture below, we construct the input file for the index pipeline such that the text part of the question/answer is stored in answer_t, and we add an additional field type_s whose value is "question" or "answer" to separate the two types.
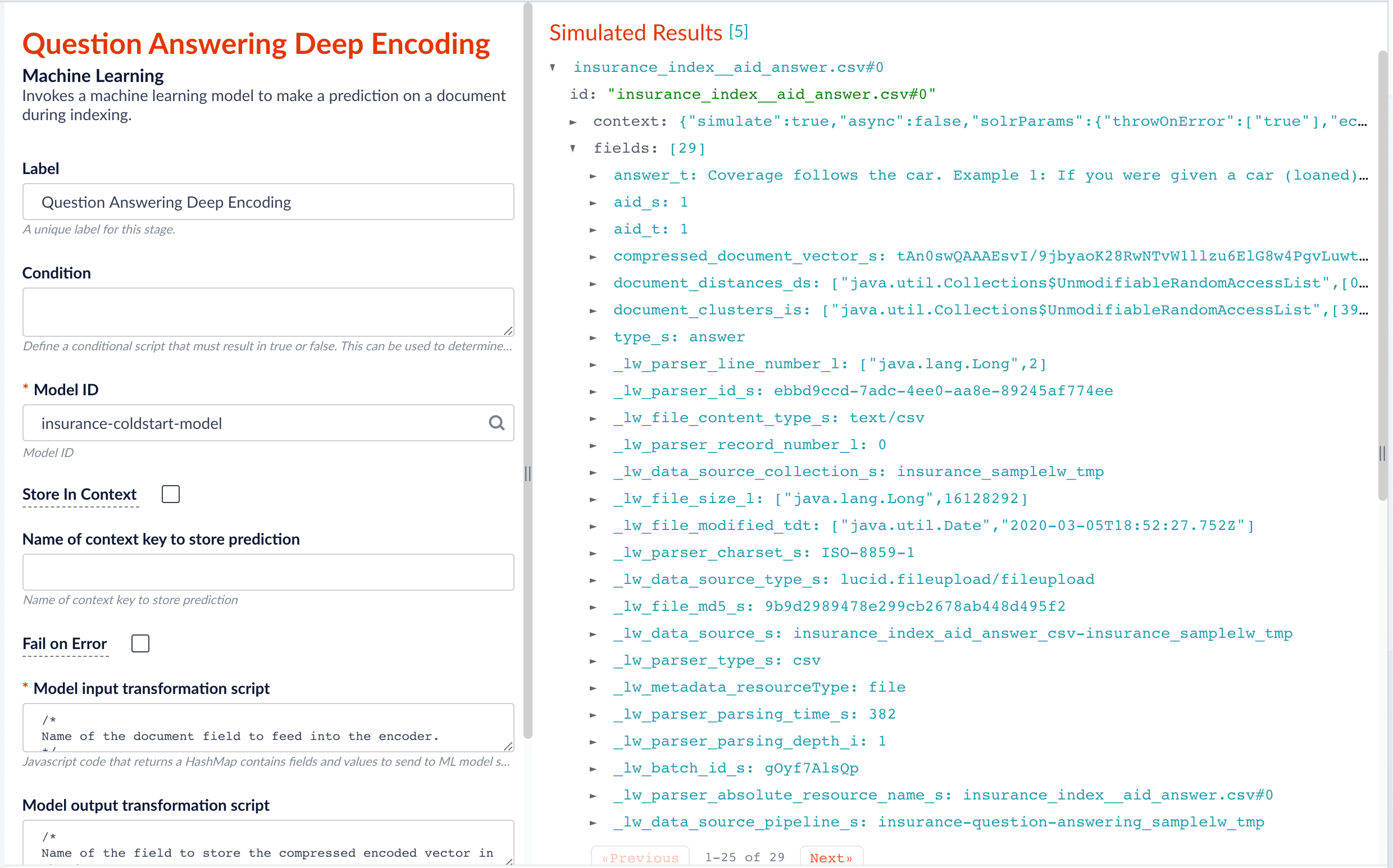
In the Machine Learning stage, we specify documentFeatureField as answer_t in the Model input transformation script so that compressed_document_vector_s is generated based on this field.
At search time, we can apply a filter query on the type_s field to return either a question or an answer.
You can achieve a similar result by using the default question-answering index and query pipelines.
(For more detail, see Smart Answers Detailed Pipeline Setup.)
Example 2: Index and retrieve the question and answer together
If you prefer to show question and answer together in one document (that is, treat the question as the title and the answer as the description), you can index them together in the same document. It’s similar to the question-answering-dual-fields index and query pipelines default setup.
For example, in the picture below, we added two Machine Learning stages and named them Answers Encoding and Questions Encoding respectively.
In the Questions Encoding stage, we specify documentFeatureField to be question_t, and change the default values for compressedVectorField, vectorField, clustersField, and distancesField to compressed_question_vector_s, question_vector_ds, question_clusters_is, and question_distances_ds respectively, in the Model output transformation script.
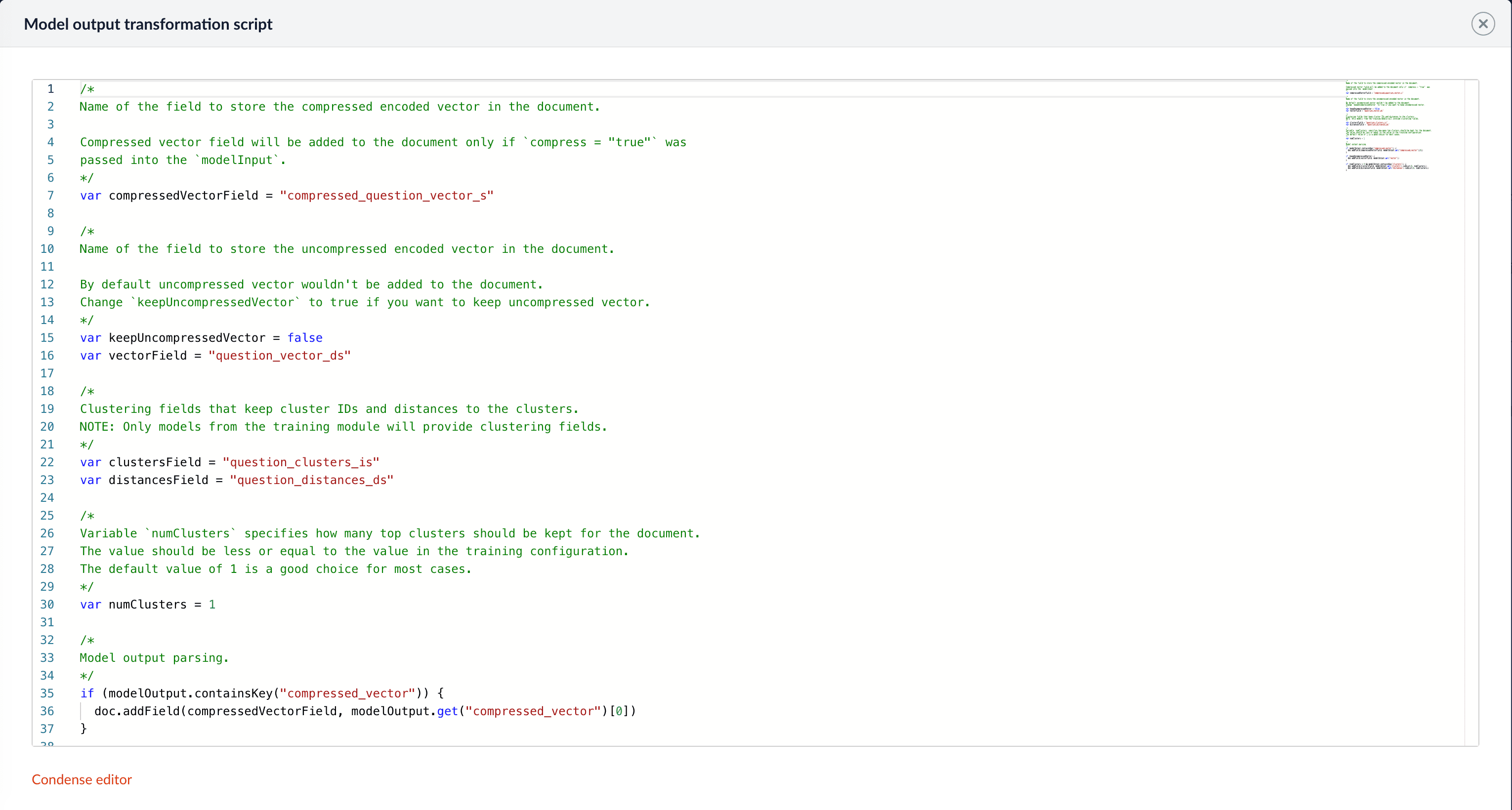
In the Answers Encoding stage, we specify documentFeatureField to be answer_t, and change the default values for compressedVectorField, vectorField, clustersField, and distancesField to answer_vector_ds, answer_clusters_ss and answer_distances_ds respectively.
(For more detail, see Smart Answers Detailed Pipeline Setup.)
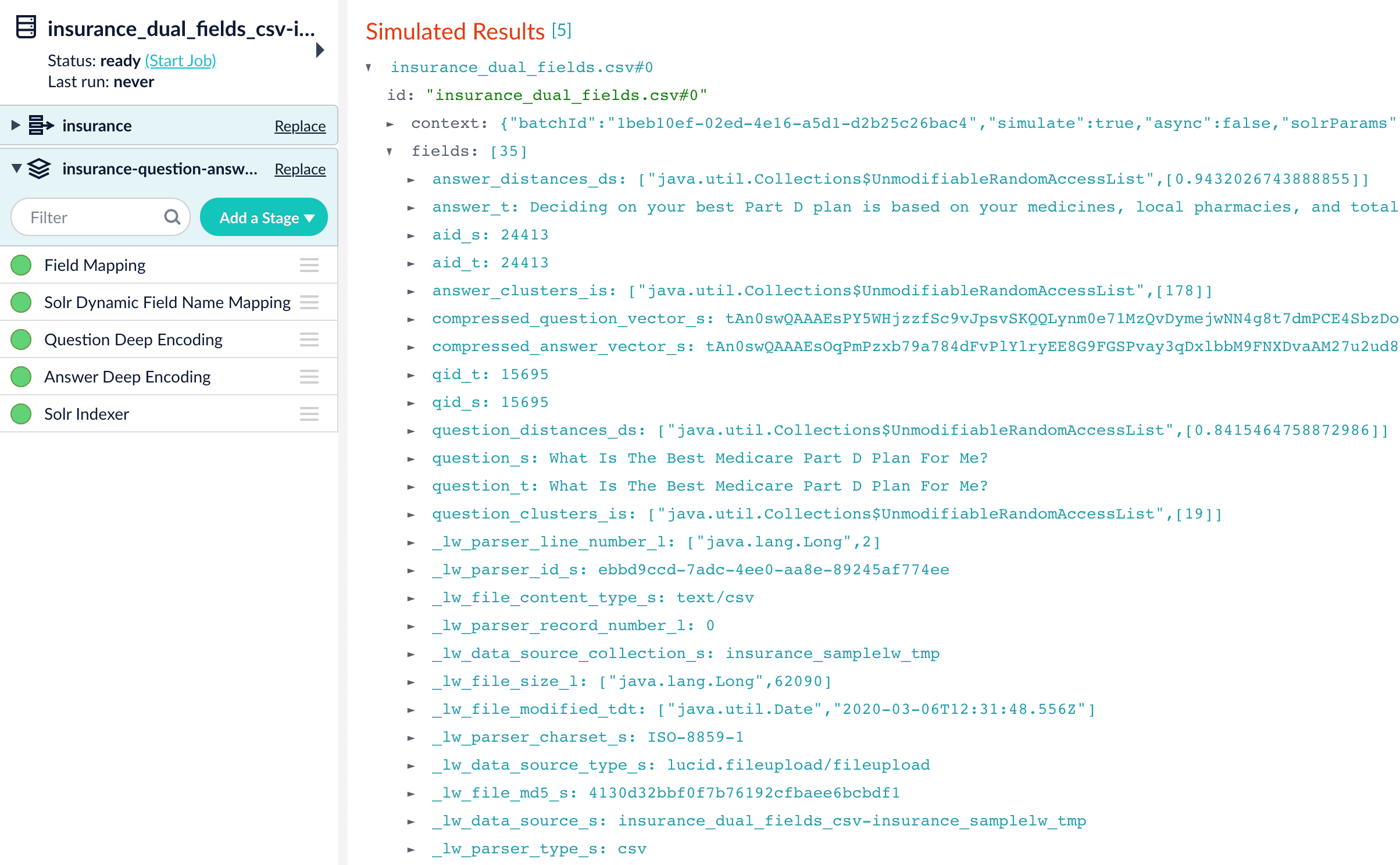
The indexed document is shown in the picture below.
Since we have two dense vectors generated in the index (compressed_question_vector_s and compressed_answer_vector_s), at query time, we need to compute query to question distance and query to answer distance. This can be setup as the picture shown below. We added two Vectors distance per Query/Document stages and named them QQ Distance and QA Distance respectively. In the QQ Distance stage, we changed the default values for Document Vector Field and Document Vectors Distance Field to compressed_question_vector_s and qq_distance respectively. In the QA Distance stage, we changed the default values for Document Vector Field, Document Vectors, and Distance Field to compressed_answer_vector_s and qa_distance respectively.
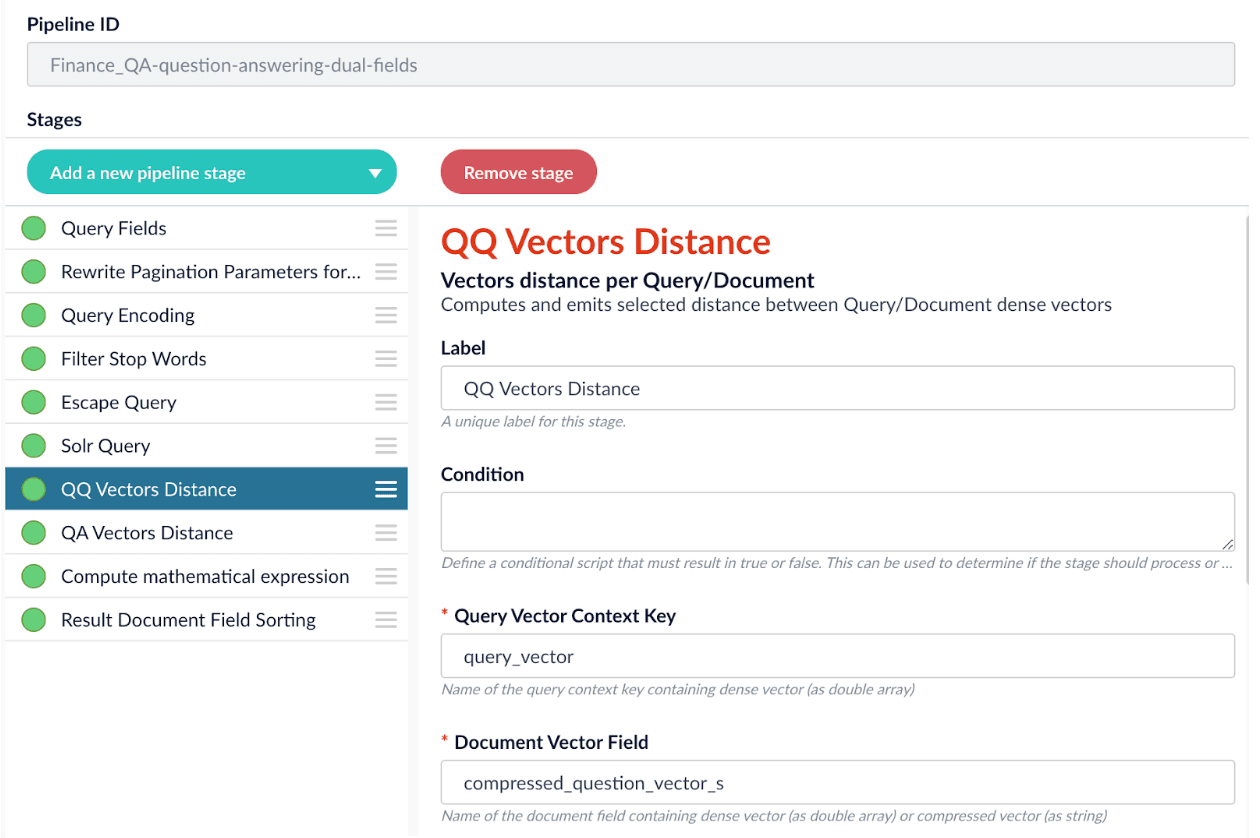
Now we have two distances (query-to-question distance and query-to-answer distance) and we can ensemble them together with Solr score to get a final ranking score. This is recommended especially when you have limited FAQ dataset and want to utilize both question and answer information. This ensemble can be done in the Compute mathematical expression stage as shown below.
Evaluate the query pipeline
The Smart Answers Evaluate Pipeline job (Evaluate QnA Pipeline job in Fusion 5.1 and 5.2) evaluates the rankings of results from any Smart Answers pipeline and finds the best set of weights in the ensemble score. See Evaluate a Smart Answers Pipeline for setup instructions.
Detailed pipeline setup
Typically, you can use the default pipelines included with Fusion AI. This topic provides information you can use to customize these pipelines. See also Configure The Smart Answers Pipelines.
"question-answering" index pipeline |
|
|
"question-answering" query pipeline |
|
Index pipeline setup
Typically, only one custom index stage needs to be configured in your index pipeline: the Machine Learning index stage.
| If you are using a dynamic schema, make sure this stage is added after the Solr Dynamic Field Name Mapping stage. |
There are several required parameters:
-
Model ID. The ID of the model.
-
Model input transformation script. Configures input to the model.
-
documentFeatureField. The text field to encode to the dense vectors, such asanswer_torbody_t(the default value).
-
-
Model output transformation script. Maps model output into the document fields.
-
compressedVectorField. The field that stores compressed dense vectors. Fusion compresses dense vectors to strings. The compressed version is used as the default to get better query runtime performance. Default value:compressed_document_vector_s. -
keepUncompressedVector. Specifies should uncompressed vector be stored in Solr. Uncompressed vectors require more storage and it’s not recommended to return it during the query time as it might affect query performance. Default value:false -
vectorField. The field that stores uncompressed dense vectors. It’s stored only ifkeepUncompressedVectoris set totrue. Default value:document_vector_ds -
clustersField. The field that stores answer clusters IDs. Default value:document_clusters_ss. -
distancesField. The field that stores distances between a document vector and its closest cluster centers. This can be used for eDiscovery purposes. For example, we can explore the clusters by sorting documents in ascending order based on this distance to clusters centers. Default value:document_distances_ds. -
numClusters. This value denotes how many clusters each document can belong to. In most cases it’s better to use just one or two clusters, since we already provide a query pipeline stage to find multiple clusters at query time.This value should be less than or equal to the number of clusters specified in the model training. Default value: 1.
-
Model input transformation script
/*
Name of the document field to feed into the encoder.
*/
var documentFeatureField = "body_t"
/*
Model input construction.
*/
var modelInput = new java.util.HashMap()
modelInput.put("text", doc.getFirstFieldValue(documentFeatureField))
modelInput.put("pipeline", "index")
modelInput.put("compress", "true")
modelInput.put("unidecode", "true")
modelInput.put("lowercase", "false")
modelInputModel output transformation script
/*
Name of the field to store the compressed encoded vector in the document.
Compressed vector field will be added to the document only if `compress = "true"` was
passed into the `modelInput`.
*/
var compressedVectorField = "compressed_document_vector_s"
/*
Name of the field to store the uncompressed encoded vector in the document.
By default uncompressed vector wouldn't be added to the document.
Change `keepUncompressedVector` to true if you want to keep uncompressed vector.
*/
var keepUncompressedVector = false
var vectorField = "document_vector_ds"
/*
Clustering fields that keep cluster IDs and distances to the clusters.
NOTE: Only models from the training module will provide clustering fields.
*/
var clustersField = "document_clusters_is"
var distancesField = "document_distances_ds"
/*
Variable `numClusters` specifies how many top clusters should be kept for the document.
The value should be less or equal to the value in the training configuration.
The default value of 1 is a good choice for most cases.
*/
var numClusters = 1
/*
Model output parsing.
*/
if (modelOutput.containsKey("compressed_vector")) {
doc.addField(compressedVectorField, modelOutput.get("compressed_vector")[0])
}
if (keepUncompressedVector) {
doc.addField(vectorField, modelOutput.get("vector"))
}
if (numClusters > 0 && modelOutput.containsKey("clusters")) {
doc.addField(clustersField, modelOutput.get("clusters").subList(0, numClusters))
doc.addField(distancesField, modelOutput.get("distances").subList(0, numClusters))
}Query pipeline setup
In the "question-answering" query pipeline, all stages (except the Solr Query stage) can be tuned for better Smart Answers:
Optionally, you can also:
-
Configure the number of clusters used in deep encoding
The Query Fields stage
The first stage is Query Fields which should have one main parameter specified:
-
Return Fields. Since documents should be retrieved with vectors and clusters, make sure to include the documents’ Vector Field and Clusters Field, which are
compressed_document_vector_sanddocument_clusters_ssby default.
The Rewrite Pagination Parameters for Reranking stage
The Rewrite Pagination Parameters for Reranking query stage is used to specify how many results from Solr should be used to create a pool of candidates for further re-ranking via model. It’s done under the hood, so users would still see the number of results controlled by "start" and "rows" query parameters.
-
Number of Results. Number of results to request from Solr, to be re-ranked by downstream stages. Default value:
500. This parameter affects both results accuracy and query time performance. Increasing the number can lead to better accuracy but worse query time performance and vice versa.This parameter can be dynamically overwritten by rowsFromSolrToRerankraw query parameter in the request.
The Filter Stop Words stage
When limited data is provided to train FAQ or coldstart models, the model may not be able to learn the weights of stop words accurately. Especially when using Solr to retrieve the top x results (if Number of Clusters is set to 0 in the Machine Learning stage), stop words may have high impact on Solr. User can use this stage to provide customized stop words list by providing them in Words to filter part of the stage.
See Filter Stop Words for reference information. See also Best Practices.
The Machine Learning ("Query Encoding") stage
The Machine Learning query stage configuration is very similar to the index stage.
| If you are using the cluster retrieval configuration in Example 1, then this stage should be located before the Solr Query stage. |
The important configuration keys are as follows:
-
Model ID. This is the model deployment name you chose when you configured the model training job
-
Model output transformation script. Maps model output into the document fields
-
documentClustersField. Document clusters Solr field name. If clustering is used then Filter Query is constructed against this field to return all documents that have the same clusters as the query. This concept is similar to Inverted File Index (IVF).Only models from the training module support clustering. Default value: document_clusters_is -
numClusters. The number of clusters that should be used for each query. This value should be less than or equal to the number of clusters specified in the model training. Default value: 0By default it is set to 0 which means that clustering is not used. Fusion returns a pool of candidates based solely on the Solr score, then performs re-ranking. If you want to use clustering, value 10 is a good choice for most cases. If the number of clusters is greater than 0 and the search term is *:*, there will be a limited number of documents shown in the result rather than showing the whole collection. That’s because*:*will be assigned to certain clusters.
-
Model input transformation script
/*
Model input construction.
*/
var modelInput = new java.util.HashMap()
modelInput.put("text", request.getFirstParam("q"))
modelInput.put("pipeline", "query")
modelInput.put("compress", "false")
modelInput.put("unidecode", "true")
modelInput.put("lowercase", "false")
modelInputModel output transformation script
/*
Document clusters Solr field name. If clustering is used then Filter Query is
constructed against this field to return all documents that have the same clusters as
query. This concept is similar to Inverted File Index (IVF).
NOTE: Only models from the training module support clustering.
*/
var documentClustersField = "document_clusters_is"
/*
Variable `numClusters` specifies how many top clusters should be used for each query.
The value should be less or equal to the value in the training configuration.
By default it is set to 0 which means that clustering is not used. If you want to use
clustering, value 10 is a good choice for most cases.
*/
var numClusters = 0
/*
Model output parsing.
*/
var queryVector = modelOutput.get("vector").stream().mapToDouble(function(d){return d}).toArray()
context.put("query_vector", queryVector)
if (numClusters > 0 && modelOutput.containsKey("clusters")) {
clusters = Java.from(modelOutput.get("clusters").subList(0, numClusters))
if (clusters.length > 1) {
fq = documentClustersField+":("+clusters.join(' OR ')+")"
} else {
fq = documentClustersField+":"+clusters[0]
}
request.putSingleParam("q", "*:*")
request.addParam("fq", fq)
}The Escape Query stage
The Escape Query query stage escapes Lucene/Solr reserved characters in a query. In the Smart Answers use case, queries are natural-language questions. They tend to be longer than regular queries and with punctuation which we do not want to interpret as Lucene/Solr query operators.
The Query-Document Vectors Distance stage
The Query-Document Vectors Distance query stage computes the distance between a query vector and each candidate document vector. It should be added after the Solr Query stage.
-
Query Vector Context Key. The context key which stores dense vectors. It should be set to the same value as _Vector Context Key _in the Machine Learning stage. Default value:
query_vector. -
Document Vector Field. The field which stores dense vectors or their compressed representations. It should be the same as _Vector Field _in Machine Learning stage. Default:
compressed_document_vector_s. -
Keep document vector field. This option allows you to keep or drop returned document vectors. In most cases it makes sense to drop document vectors after computing vector distances, to improve run time performance. Default:
False (unchecked). -
Distance Type. Choose one of the supported distance types. For a FAQ solution,
cosine_similarityis recommended, which produces values with a maximum value of 1. Higher value means higher similarity. Default:cosine_similarity. -
Document Vectors Distance Field. The result document field that contains the distance between its vector and the query vector. Default:
vectors_distance.
The Compute Mathematical Expression stage
We can use the Compute Mathematical Expression query stage to combine the Solr score with the vectors similarity score to borrow Solr’s keywords matching capabilities. This stage should be set before the Result Document Field Sorting stage. Result field name in this stage and Sort field in the Result Document Field Sorting stage should be set to the same value.
-
Math expression. Specify a mathematical formula for combining the Solr score and the vector similarity score. Note that Solr scores do not have an upper bound, so it is best to rescale it by using the
max_scorevalue, which is the max Solr score from all returned docs.vectors_distanceis the cosine similarity in our case and it already has an upper bound of 1.0. The complete list of supported mathematical expressions is listed in the Oracle documentation.Default:
0.3 * score / max_score + 0.7 * vectors_distanceWe recommend adjusting the ratios 0.3 and 0.7 to other values based on query-time evaluation results (mentioned in the section above). Feel free to try other math expressions (such as log10) to scale the Solr score as well. -
Result field name. The document field name that contains the combined score. The same value should be set in the Result Document Field Sorting stage, in the Sort Field parameter. Default:
ensemble_score
The Result Document Field Sorting stage
Finally, the Result Document Field Sorting stage sorts results based on vector distances obtained from the previous Vectors distance per Query/Document stage or ensemble score from Compute mathematical expression stage.
-
Sort Field. The field to use for document sorting. Default value:
ensemble_score -
Sort order. The sorting order: (asc)ending or (desc)ending. If
cosine_similarityis used with higher values meaning higher similarity, then this should be set todesc. Default:desc.
Configuring the number of clusters
Another important parameter to choose is the Number of clusters parameter in the Machine Learning stage in the query pipeline. There are two options for utilizing the dense vectors from a query pipeline:
-
If set Number of clusters parameter to 0 (default option), then we use Solr to return the top x results, then re-rank using vector cosine similarity, or combine the Solr score with the vector score using our Compute mathematical expression stage. If you choose this option, then adjust Number of Results parameter (Default value 500) in the Rewrite Pagination Parameters for Reranking stage in the query pipeline. This parameter controls how many documents to be returned from Solr to Fusion and re-ranked under the hood. You can adjust this parameter to find a good balance between relevancy and query speed.
-
If you set the Number of clusters parameter to a value x greater than 0, when a query comes in, Fusion transfers the query into a dense vector and find the closest x clusters to which the query belongs. The pipeline then obtains documents from the same clusters as query and re-ranks them based on the vector cosine similarity between the query and the indexed answers/questions. The good default values can be 1 cluster per document and 10 clusters per query.
Documents from the clusters might be obtained in the following ways:
-
By using Solr search. Then search space is narrowed by both clusters and Solr. And Solr score might be used in the ensemble in the same way as in the first option described above.
-
By using only clusters. Then all documents from certain clusters are retrieved for re-ranking. Solr doesn’t narrow the search space, but it’s also not used for ensemble.
Comprehensive evaluation should be done to decide which approach to use.
Short answer extraction
By default, the question-answering query pipelines return complete documents that answer questions. Optionally, you can extract just a paragraph, a sentence, or a few words that answer the question. See Extract Short Answers from Longer Documents.